MIST & MIST FXXKER Lora Trianing TEST
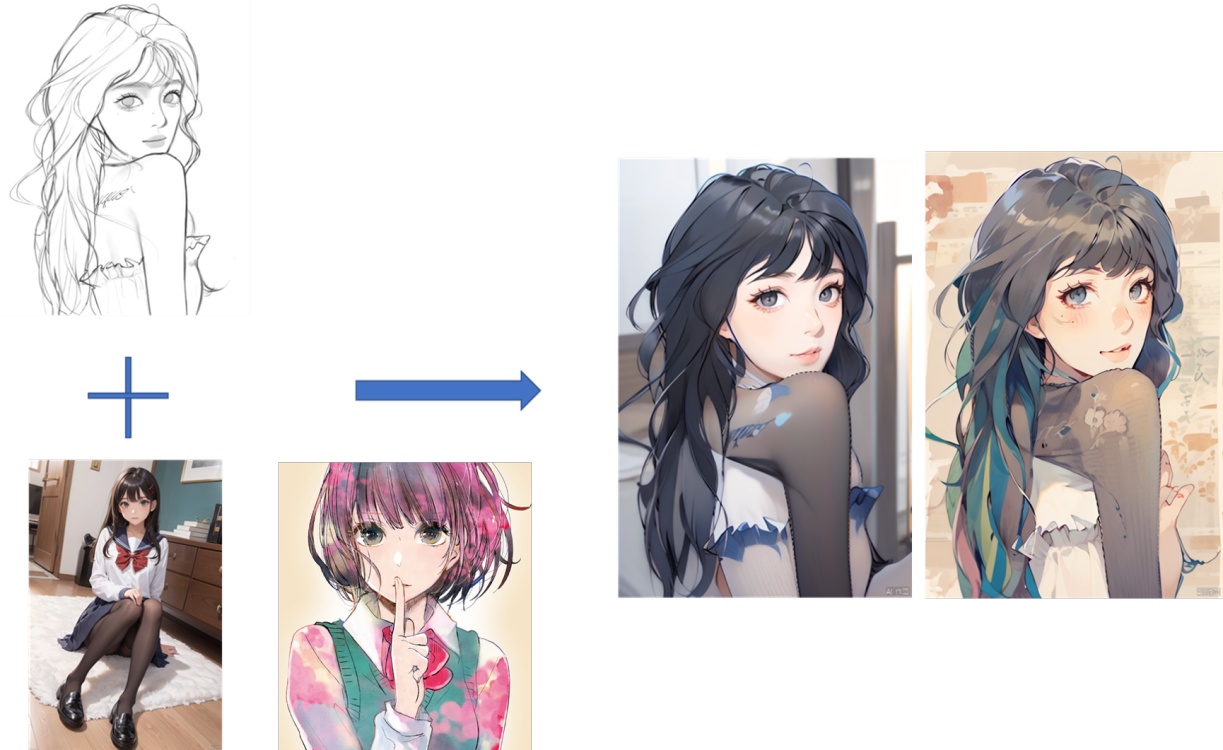
"主不在乎" ----《三体·黑暗森林》"光锥之内就是命运"mist github url/项目地址mist fxxker本次测试所用训练数据集和成品LORA/train data&lora file in this test相关清理代码/测试图片/训练设置在本页附件内原文地址:MIST & MIST FXXKER Lora Trianing TEST | Civitai微博上看到个很有趣的项目,声称可以保护图片使其无法训练。”Mist是一项图像预处理工具,旨在保护图像的风格和内容不被最先进的AI-for-Art应用程序(如Stable Diffusion上的LoRA,SDEdit和DreamBooth功能和Scenario.gg等)模仿。通过在图像上添加水印,Mist使AI-for-Art应用程序无法识别并模仿这些图像。如果AI-for-Art应用程序尝试模仿这些经Mist处理过的图像,所输出的图像将被扰乱,且无法作为艺术作品使用。“https://weibo.com/7480644963/4979895282962181https://mist-project.github.io/下载,这个项目环境配置本身比较困难,而且刚性需求bf16(在一台2080ti设备测试,其实有一部分可以运行在fp16上,但急着测试没时间修改代码,本机有4090重新配环境太麻烦),最后还是请朋友帮忙处理了图片。本次测试所用训练集/原图/lora文件已附上,请自取。MIST & MIST FXXKER Lora Trianing TEST LORA and Dat - train_data | 吐司tusi.cn测试介绍/Introduction to testing测试图片/Testing images本次测试图片分为四组。通过爬虫获取的原图。经过mist v2在默认配置下处理的原图。mist-fxxker,使用第一阶段clean 处理[2]图片(注:该阶段处理耗时约25s/106张图@8c zen4)mist-fxxker, 使用clean+SCUNET+NAFNET 处理[2]图片(注,该阶段8s/每张图@4090)测试模型&参数/base model &parameter testing1.训练使用nai 1.5 ,7g ckpt.MD5: ac7102bfdc46c7416d9b6e18ea7d89b0SHA256:a7529df02340e5b4c3870c894c1ae84f22ea7b37fd0633e5bacfad96182280322.出图使用anything3.0MD5:2be13e503d5eee9d57d15f1688ae9894SHA256:67a115286b56c086b36e323cfef32d7e3afbe20c750c4386a238a11feb6872f73.参数因本人太久没有训练1.5lora,参考琥珀青叶推荐&经验小幅度修改。4.图片采用narugo1992 所推荐的three stage切片方法处理(小规模测试里,未经three stage处理放大特征的话,很难学习到mist v2的效果)测试流程/Testing Process通过爬虫获取booru上一定数量柚鸟夏图片通过mist v2 & mist fxxker 处理,获取剩余三组图片。把四组图片当作下载后原图,引入训练工作流,进行打标,识别,切片,处理后获取四组训练集。用这四组训练集训练产生对应lora测试lora测试结果/Results说明:结合图片观感,本人认为在15ep以后,已经基本达成了角色拟合和训练需求,正常训练时也不会超过这么多ep,因而测试基于15ep,其余lora和训练集请自取测试。总测试参数/Total test parameterDPM++ 2M Karras,40steps,512*768,cfg 7if Hires. fix:R-ESRGAN 4x+ Anime6B 10steps 0.5all neg:(worst quality, low quality:1.4), (zombie, sketch, interlocked fingers, comic) ,Trigger Words:natsu \(blue archive\)直接出图测试/Direct testing测试1:prompts:natsu \(blue archive\),1girl, halo,solo, side_ponytail, simple_background, white_background, halo, ?, ahoge, hair_ornament, juice_box, looking_at_viewer, milk_carton, drinking_straw, serafuku, blush, long_sleeves, red_neckerchief, upper_body, holding, black_sailor_collar,测试2:natsu \(blue archive\),1girl, solo, halo, pleated_skirt, black_sailor_collar, side_ponytail, milk_carton, chibi, black_skirt, puffy_long_sleeves, ahoge, white_cardigan, white_footwear, black_thighhighs, shoes, white_background, v-shaped_eyebrows, full_body, +_+, blush_stickers, standing, sparkle, two-tone_background, holding, twitter_username, :o, red_neckerchief, serafuku, pink_background, open_mouth测试3:prompts:natsu \(blue archive\),1girl, cherry_blossoms, outdoors, side_ponytail, solo, black_thighhighs, halo, drinking_straw, ahoge, tree, white_cardigan, looking_at_viewer, milk_carton, long_sleeves, pleated_skirt, day, neckerchief, open_mouth, holding, juice_box, black_sailor_collar, blush, black_skirt, serafuku, building, zettai_ryouiki小结:测试原图放在附件了,可以自行对比查看。就目前测试而言,单步骤的clean过后,即便放大后仔细查看,肉眼也很难分辨图片是否经过mistv2污染。即便不经过任何处理,mist的污染也需要放大图片同时提高显示器亮度才能发现(这是100%污染图源作为训练素材)项目地址展示结果目前暂时无法复现。直接出图后高清修复测试after Hires. fix经过上一步,下面我们只测试经过mistv2处理后训练集直出的lora在higher fix后的表现高清修复参数: R-ESRGAN 4x+ Anime6B 10steps 0.5出图后清洗只经过clean特别加测不使用three stage的结果:SD1.5 补充测试/add test论文里使用的是sd1.5底模,因此简单尝试了一下在sd1.5能否复现论文所展示的model attack性能。图片显示即便被攻击过的数据集也并没有影响到对角色特征的学习,mistv2带来的污染在使用对应lora后也能够清除。其他方面不太能确定,毕竟sd1.5模型对于二次元角色本身就是个灾难,自己看图吧。MIST & MIST FXXKER Lora Trianing TEST LORA and Dat - lora_sd1.5 | 吐司tusi.cn总结/Summary什么样情况下lora会受到mistV2的影响1.训练集没有经过常见的预处理流程2.使用了three stage方法3.mist v2处理后图片比例占绝对优势。1,2,3任何一项的缺失都会让mist V2的效果显著下降。污染了怎么办1.训练前:请使用最简单的方法清除即可,0.25s/per image。2.训练后:请以适当的负数权重合并调整loraAdjusting Mist V2 effect / Mist V2 效果调节- v1.0 | 吐司3.出图阶段: 同上,可以请谁写个小扩展?评价/Evaluationit is better than nothing.