



受限于字数限制:前置内容Stable Diffusion WebUI 从入门到卸载 | 吐司 tusi.cn
模型训练的问题
部分模型训练的时候出现的问题也会导致提示词出现不听话的情况。
许多 tag 有着逻辑上合理的“前置”关系,比如存在 sword 这个 tag 的作品往往还存在 weapon 这个 tag、存在 sleeves past finger 这个 tag 的作品往往还存在 sleeve past wrists 这个 tag。
这样在训练集中往往共存且有强关联的 tag,最终会让模型处理包含它的咒语时产生一层联想关系。
不过上述联想关系似乎不够令人感兴趣,毕竟这些联想的双方都是同一类型,哪怕 sword 联想了 weapon 也只是无伤大雅。那么是否存在不同类型的联想呢?
答案是存在的:

masterpiece, 1 girl, blue eyes, white hair, white dress, dynamic, full body, simple background
masterpiece, 1 girl, blue eyes, white hair, white dress, (flat chest), dynamic, full body, simple background不难发现 flat chest 除了影响人物的胸部大小之外还影响了人物的头身比,让人物的身高看上去如同儿童身高一般,如果调整画布为长画布还会更明显。因此称 flat chest 与 child 有着联想关系。人物胸部大小和身高是不同的两个类型,两个看似类型完全不同的词也可以产生联想关系。对 flat chest 加大权重,会让这种联想关系会表现地更为突出。
它的原理和上述同类型的联想一样,都是训练来源导致的。平胸美少女和儿童身高在同一个作品内出现的概率非常大,模型训练的时候不做好区分就会混在一起产生联想关系。这种联想关系在社区中曾被称为“零级污染”。
这种现象在不同的模型中的表现是不同且普遍存在的:
例如:在cf3模型中,出现了又rain的情况下一定会存在雨伞的关联现象。rain和unbrella产生了联想关系。
9. 如何使用LoRA
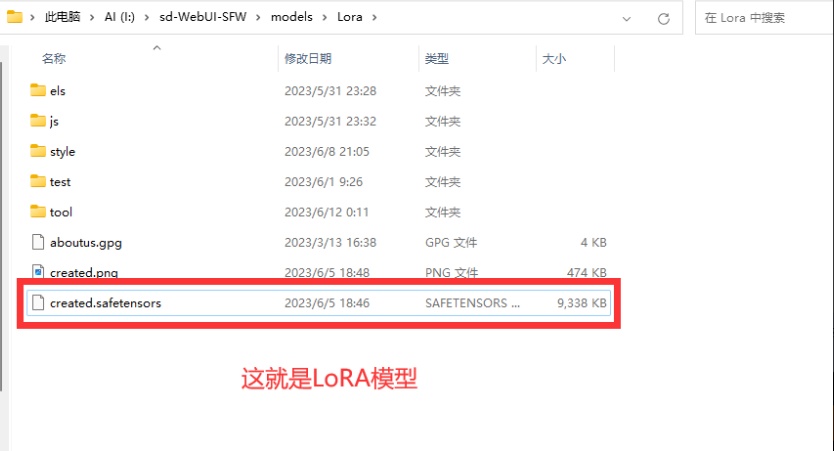
①首先,把你的LoRA模型放到指定文件夹(你的webui根目录\models\Lora)里面文件夹和我的不一样没关系,只要把模型放到这里就行了。如果下载了太多的LoRA模型不好找,那么就可以像我一样加入文件夹分类
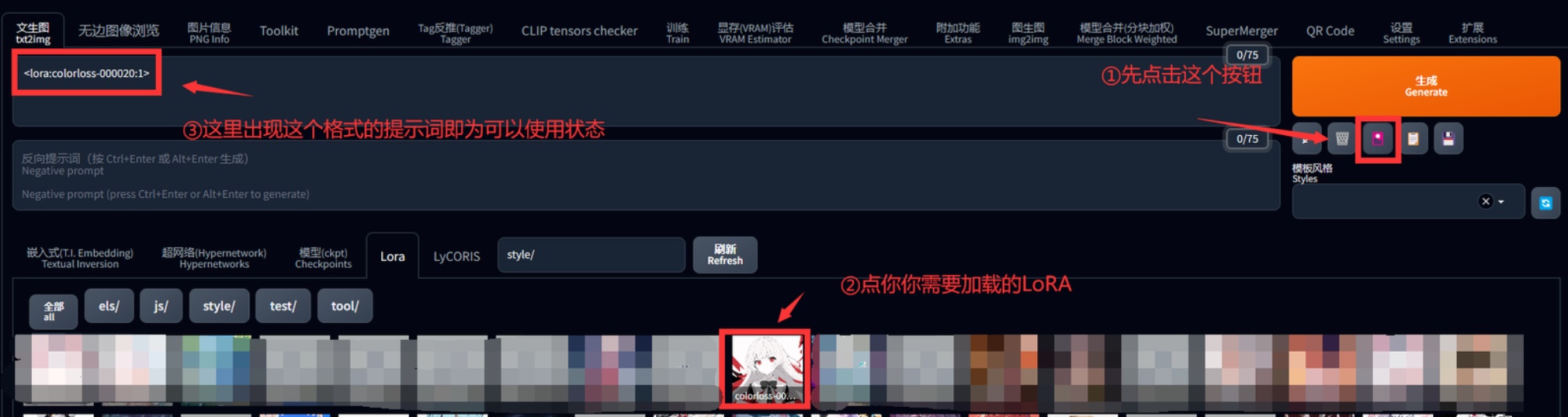
②按照图片提示,依次点击LoRA列表按钮——想要使用的LoRA,在正面提示词栏里出现 <lora:colorloss-000020:1>这种格式的提示词即为下一次生成所要加载的LoRA。
③如果你使用安装了Kitchen主题或者用了kitchen主题套壳的整合包,那么你的LoRA在这里
10. 画大大大大大大的图
Tiled VAE
扩展插件: pkuliyi2015/multidiffusion-upscaler-for-automatic1111
Tiled VAE能让你几乎无成本的降低显存使用
● 您可能不再需要 --lowvram 或 --medvram。
● 以 highres.fix 为例,如果您之前只能进行 1.5 倍的放大,则现在可以使用 2.0 倍的放大。
使用方法:
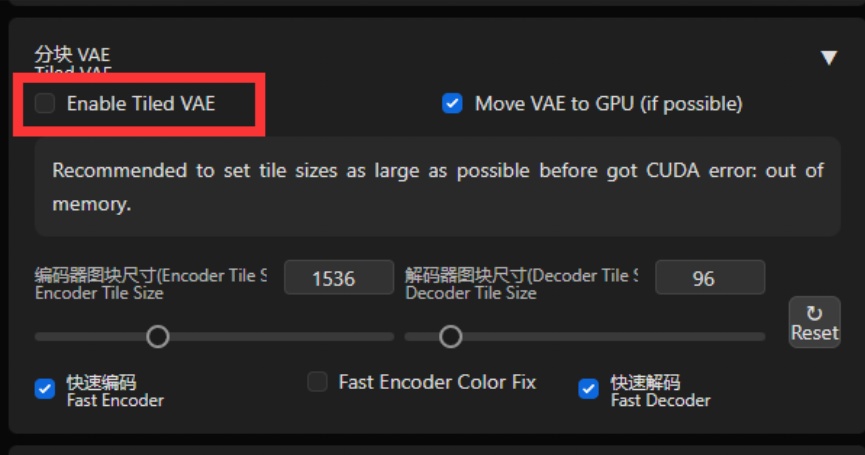
勾选红框所示的勾选框以启动Tiled VAE
在第一次使用时,脚本会为您推荐设置。
因此,通常情况下,您不需要更改默认参数。
只有在以下情况下才需要更改参数:当生成之前或之后看到CUDA内存不足错误时,请降低 tile 大小
当您使用的 tile 太小且图片变得灰暗和不清晰时,请启用编码器颜色修复。
stableSR
扩展插件:pkuliyi2015/sd-webui-stablesr: StableSR for Stable Diffusion WebUI
功能:更强大的图片放大
扩展详细用法请看以下链接:
sd-webui-stablesr/README_CN.md at master · pkuliyi2015/sd-webui-stablesr · GitHub
11. 元素同典:真正的parameters魔法入门
我们保留了一点点Junk Data:请选择你的模型
1. Stable Diffusion的工作原理
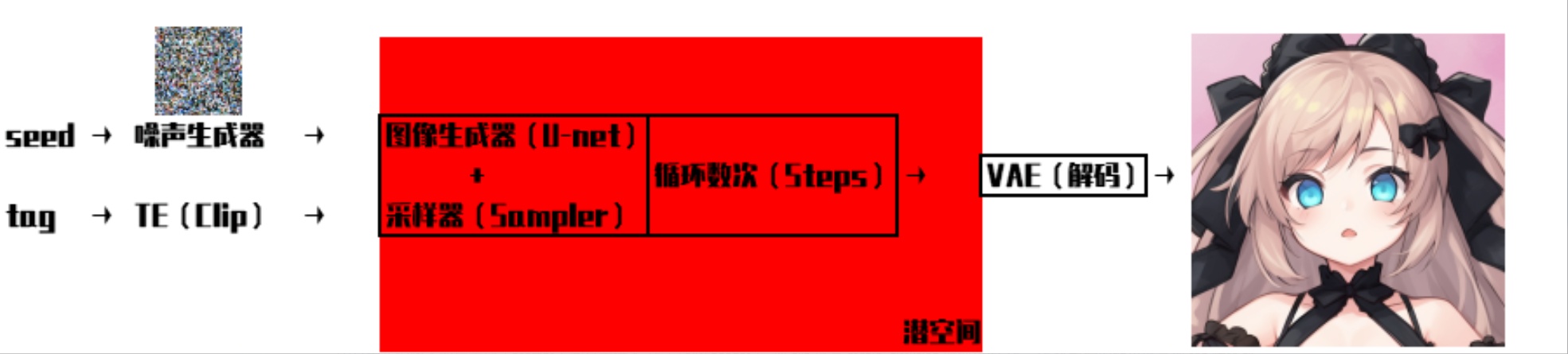
①首先我们输入的提示词(prompt)会首先进入TE(TextEncoder),而clip就是stable diffusion所使用的TE。TE这部分的作用就是把tag转化成U-net网络能理解的embedding形式,当然了,我们平时用的emb模型,就是一种自然语言很难表达的promot。(简单的说就是将“人话”转换成AI能够理解的语言)
②将“人话”转换成AI能够理解的语言之后,U-net会对随机种子生成的噪声图进行引导,来指导去噪的方向,找出需要改变的地方并给出改变的数据。我们之前所设置的steps数值就是去噪的次数,所选择的采样器、CFG等参数也是在这个阶段起作用的。(简单的说就是U-net死盯着乱码图片,看他像什么,并给出更改的建议,使得图像更加想这个东西)
③一张图片中包含的信息是非常多的,直接计算会消耗巨量的资源,所以从一开始上面的这些计算都是在一个比较小的潜空间进行的。而在潜空间的数据并不是人能够正常看到的图片。这个时候就需要VAE用来将潜空间“翻译”成人能够正常看到的图片的(简单的说就是把AI输出翻译成人能看到的图片)
经过以上三个步骤,就实现了“提示词→图片”的转化,也就是AI画出了我们想要的图片。这三个步骤也就对应了模型的三个组成部分:clip、unet、VAE
2. 好模型在哪里?
同时满足:提示词准确、少乱加细节、生成图好看、模型本身没有问题的模型,我们就能称之为好模型。
提示词准确:顾名思义,就是tag提示词的辨别能力越高越好。提示词辨别能力差,那么我们就难以达到想要的效果。
少乱加细节:指的是产生提示词中并不包含的细节,并且我无法通过提示词来消除这些不相干的细节,这会影响提示词对于生成图的控制能力。
生成图好看:这没什么好说的,生成图无论如何都是炸的话,那这个模型也就没有存在的必要了。
模型本身没有问题:一般而言是指不含有Junk data和VAE没有问题的模型
3. 讨厌的junk data
junk data就是指垃圾数据,这些数据除了占用宝贵的硬盘空间外毫无作用。一个模型里只有固定的那些内容才能够被加载,多出的全是垃圾数据。一般而言一个7Gb的SD1.5模型,实际生成图片所用到的只有3.98Gb。模型并不是越大越好
这些东西大部分都是EMA,模型在Merge后EMA将不再准确反映UNET,这种情况下EMA不止没啥用,还会影响模型的训练。所以在尝试融合模型时期,请先使用工具删除模型EMA权重(后面讲模型融合的时候会提到)
4. 你的AI浓度超标了!
曾经时间大家的模型同质化都是比较严重的,按照出图效果分类可以将这一部分融合模型模型分为:橘子、蜡笔、Anything、cf等多种系列,每一种系列中的不同模型实际上都效果相差不大,完全没有必要去下载全部的模型。
不了解AI的人所说的“AI浓度超标”“AI味”,其实指的是橘子(AOM)这一系列模型的风格,具体效果是人物身体的表面有一种油光,多了解之后你就会发现,类似这种一整个系列都会有相似的风格。
5. 你的VAE?不,是你的VAE!
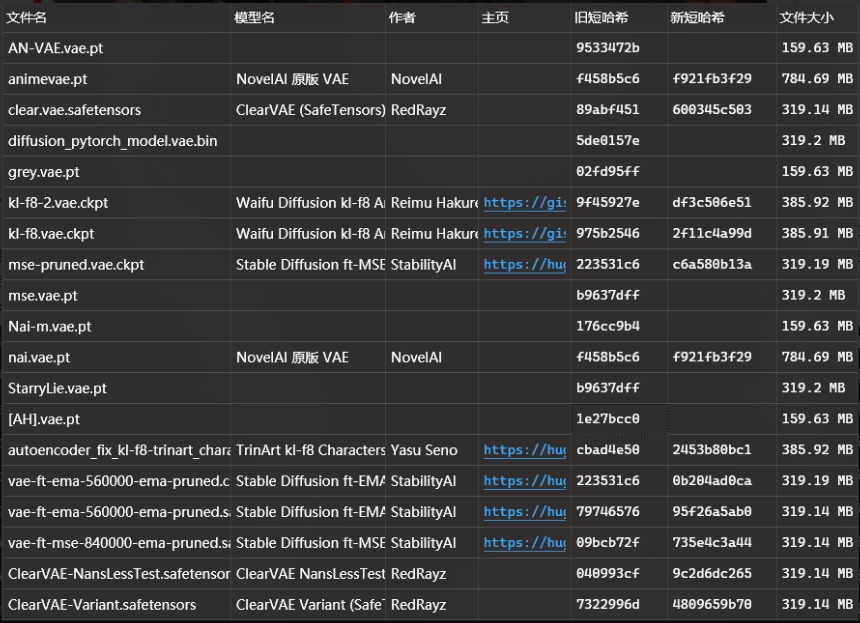
VAE重复问题在SD1.5是比较严重的,例如Anything V4.5 VAE,实际上和novelai的VAE是完全相同的,有不少模型自带的VAE是使用了其他的VAE并且只是更改了文件名称而已,实际上这些VAE的哈希值都是完全相同的。相同的VAE无需重复下载,这些完全重复的VAE除了占用宝贵的硬盘空间外毫无作用。
下面是笔者这里所有的VAE的哈希对照:(当然并不是全部,肯定还有其他的)
掌控全局:ControlNet控制网
ControlNet是stable diffusion的一个插件,它可以通过添加条件图片的形式来自定义很多内容达到自己想要的效果
扩展插件: Mikubill/sd-webui-controlnet
ControlNet的保存库: lllyasviel/ControlNet
1. ControlNet基本功能
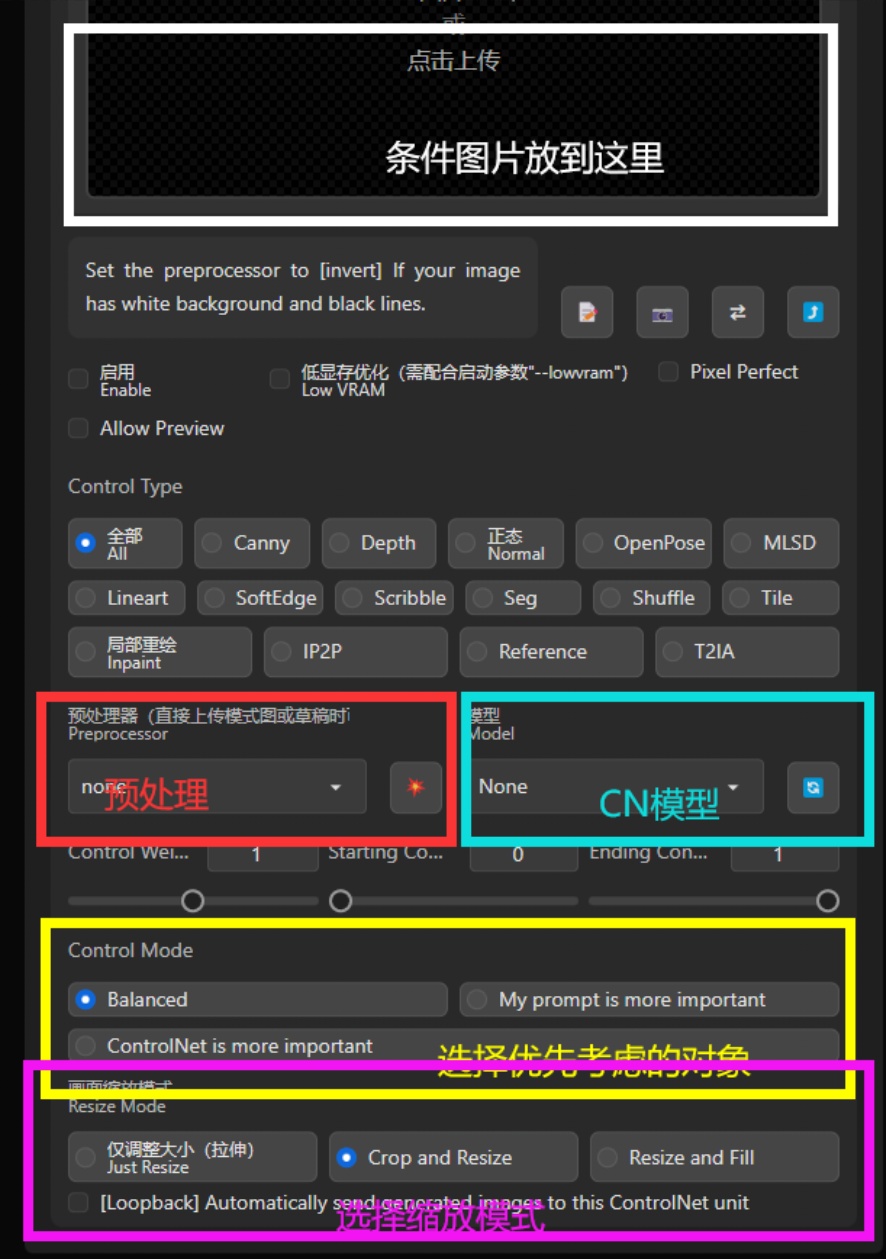
想要使用控制网,首先需要点击启用(Enable)不然再怎么调整都是没有任何效果的(不启用怎么可能有效果)
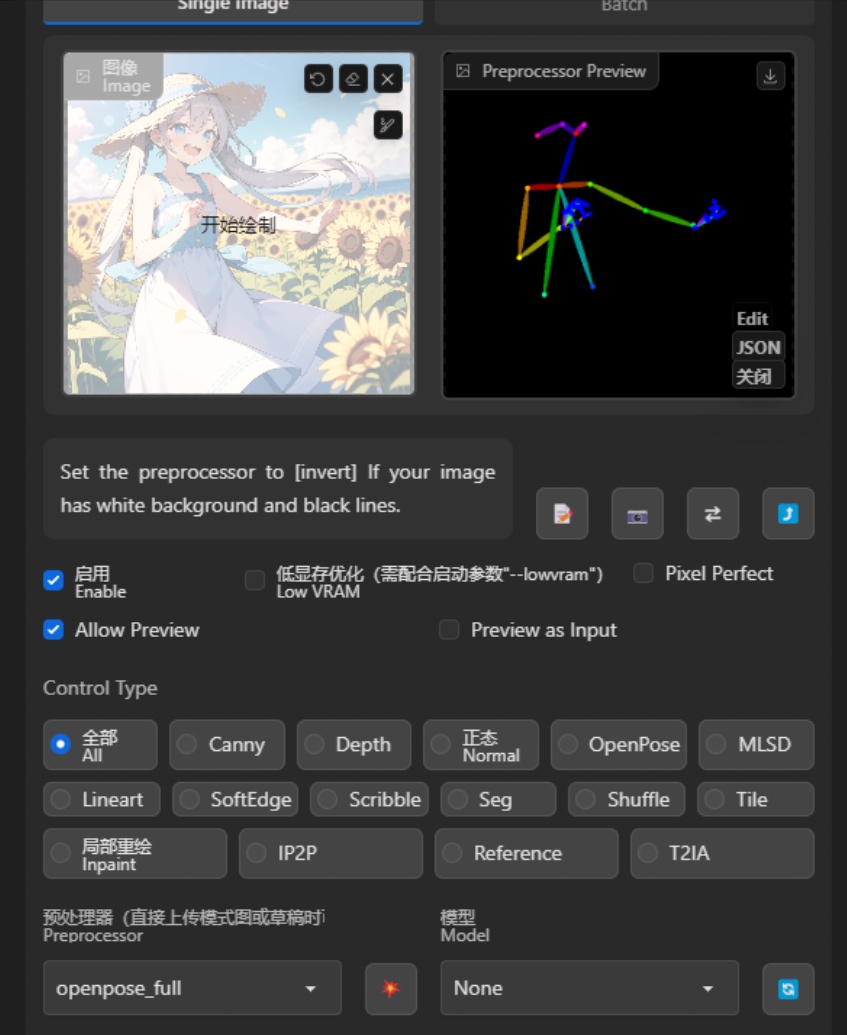
图片位置:你可以选择需要使用的图片导入至此,用以制作模板
预处理:指你想要如何处理上传的模板图片。对应的控制网模型需要与之相对应的模板。
CN模型:选择你要使用的模型,例如人物姿态控制就需要使用openpose,想要切换图片的白天黑夜状态就需要使用shuffle,不同的模型对应不同的功能
选择优先考虑对象:给提示词更好的表现还是给控制网更好的表现
选择缩放模型:你可以类比为windows系统的壁纸,可以调整生成图和模板分辨率不同的时候如何处理。
Control Type:图上没标注,为不同模型的预设设置,很方便。

另外还有这三个选项也是很常用的:从左到右的顺序是控制网权重、控制网介入时机、控制网引导退出时机。实际效果顾名思义即可。
2. 推荐教程
我这里不可能讲解的面面俱到,而且很多内容仅停留在会用上,你可以查看一些up的视频来学习
ControlNet1.1场景氛围转换_哔哩哔哩_bilibili
我们可以炼丹了,你不觉得这很酷吗?(lora)
1. 没有脚本,炼个P
这里推荐使用秋叶的LoRA模型训练包
https://www.bilibili.com/video/BV1AL411q7Ub/
也可以使用Kohya的训练脚本
kohya-ss/sd-scripts (github.com)
或者是HCP-diffusion(相信会用这个的大概不会来看这个入门级文章的吧)
7eu7d7/HCP-Diffusion: A universal Stable-Diffusion toolbox (github.com)
不推荐使用任何预设参数的一键炼丹炉
2. 开始训练的准备工作
①首先你需要一个6GB以上显存的NVIDIA显卡,如果没有,可以尝试云端炼丹
②你需要一个祖宗级基础模型sd1.5 2.0、novelai,不推荐使用任何融合模型。
③如果使用非秋叶包,那么你还需要在webui上使用tagger插件
④准备训练集:
训练集打标可以使用秋叶整合包中的tagger模块,也可以使用webui中的tagger插件。但是需要注意:任何AI打标都不可能100%准确,有条件尽可能人工筛查一遍,剔除错误标注
一般而言需要准备一个训练集文件夹,然后文件夹中套概念文件夹

命名格式为:x_概念tag
x为文件夹中图片的重复次数(repeat)
【这个参数不在训练UI里调节,而是直接在文件夹名称上调节】
训练集是LoRA训练的重中之重,训练集直接决定了LoRA模型的性能
3. 你所热爱的,就是你的参数
①学习率设置
UNet和TE的学习率通常是不同的,因为学习难度不同,通常UNet的学习率会比TE高 。
我们希望UNet和TE都处于一个恰好的位置,但是这个值我们不知道。
如果你的模型看起来过度拟合,它可能训练Unet过头了,你可以降低学习率或更少的步数来解决这个问题。如果你的模型生成噪点图/混乱难以理解的图片,那至少需要在学习率的小数点后面加个0再进行测试。
如果模型不能复刻细节,生成图一点都不像,那么就是学习率太低了,尝试增加学习率
降低TE学习率似乎对分离对象有好处。如果你在生成图片过程中发现了多余的物品,那么就需要降低TE学习率
如果您很难在不对提示进行大量权重的情况下使内容出现,那么你就需要提高TE学习率。
更好的方法是先使用默认参数训练测试,然后再根据测试的结果来调整对应的参数。(秋叶训练包里的默认参数都是自带的)
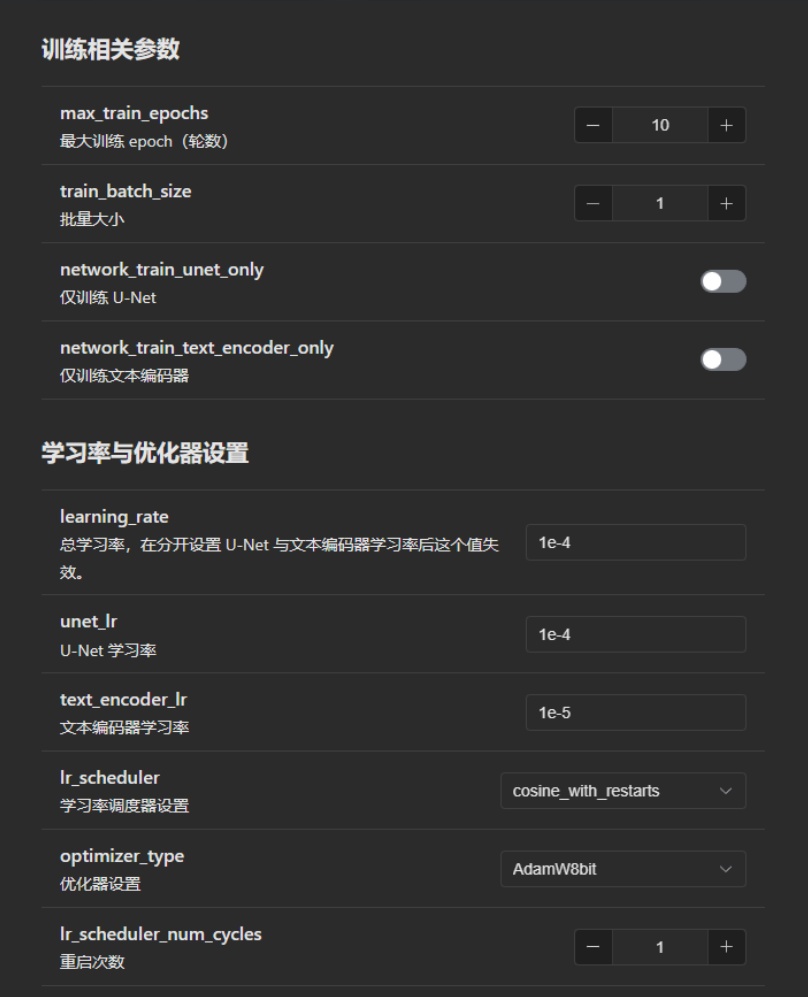
②优化器
AdamW8bit:默认优化器,一般而言不了解/不知道测试结果的直接使用这个优化器即可
AdamW:占用显存更高,但是比8bit效果更好一点
DAdaptation:自适应调整学习率,显存占用极高。有不少人使用这个优化器来摸最开始使用的学习率
SGDNesterov8bit:极慢,不推荐使用
SGDNesterov:极慢,不推荐使用
AdaFactor:(笔者没用过)似乎效果比DAdaptation好很多
Lion:占用显存较高,效果极好,但是比较难以控制,需要bs或者等效bs大于64才能达到极佳的效果。
Lion8bit:占用显存可能更低
③调度器设置
linear:不断下降,直到最后为零。
cosine:学习率呈余弦波形上下波动。
cosine_with_restarts:(没用过带其他人补充)
polynomial:类似linear,但曲线更漂亮
constant:学习率不会改变。
constant_with_warmup:类似于constant,但从零开始,并在warmup_steps期间线性增加,直到达到给定值。
④噪声设置
noise_offset:在训练中添加噪声偏移来改良生成非常暗或者非常亮的图像,如果启用推荐为 0.1
金字塔噪声:增加模型生成图亮度对比和层次感,效果极佳建议开启
4. 过拟合和污染
①触发词和过拟合,并没有十分严格的界定,除非一些lora是过拟到非常糟糕,直接吐原图那种。毕竟训练人物特征本身就需要一定的“过拟合”
②训练中常见污染,主要是因为打标器认不出或者遗漏(训练集质量),还有大模型的部分问题导致更容易被诱发的特征,包括:
1. 混入其中的奇怪动物。
2. 喜欢侧视和背视。
3. 双马尾/兽耳。
4. 胳膊喜欢披点东西(比如外套)。
出现此类情况可以先先检查训练集和标注,然后再更换模型测试
另外:角色的不对称特征请处理使其尽量在同一侧,且不要开启训练时镜像处理。
5. 删标法之争,没有绝对的对与错
在角色训练方面,一直有两种不同的观点
删除所有特征标:多用于多合一,优点是调用方便,一两个tag就能得到想要的角色特征,但缺点是
1. 一些特征可能受底模影响发生偏移。
2. 要换衣服和nsfw比较困难。
3. 容易出现不同概念的相互污染。
4. 提示词会不准确
删除部分特征标:仅删除多个决定角色特征的tag标注
全标:优点是提示词准确,但是部分角色效果可能不好出现(还原性较差)
是否删标取决于自己想要什么:假设说我的训练图是一个红色的苹果,如果我们标注这个苹果是红色的,那么你可以在生成图片的时候生成出绿色的苹果。如果我们只标注苹果,那么这个红色的就作为苹果的固有属性,只要出现苹果,那么就是红色的。
6. LoRA进阶训练方法
分层训练:https://www.bilibili.com/video/BV1th411F7CR/
完美炼丹术,差异炼丹法:https://www.bilibili.com/video/BV11m4y147WQ/
LoRA BW插件:https://github.com/hako-mikan/sd-webui-lora-block-weight
模型Merge,并不科学但确实有效
1. 你权重乱了
融合模型前请先去除模型中的EMA权重:
模型在Merge后EMA将不再准确反映UNET,这种情况下EMA不止没啥用还会占用宝贵的硬盘空间
2. 传统模型merge
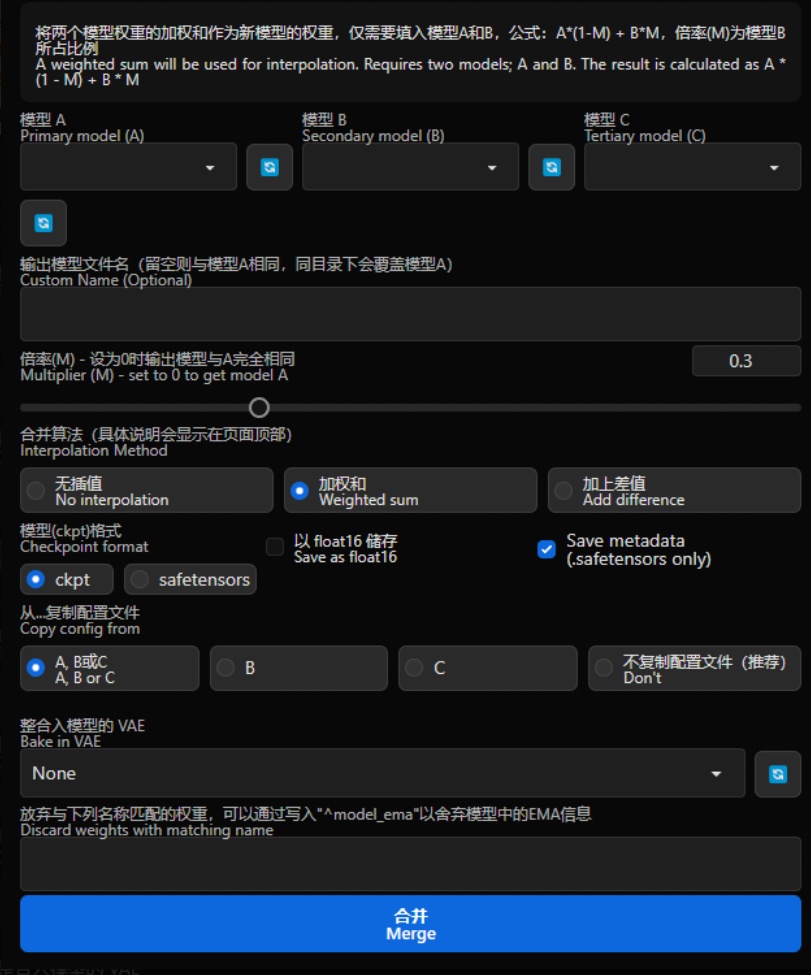
① 选择模型
A、B、C
②设置新模型名字
一般来说可以设置为xxxMix(xxx为你想要的名称,Mix代表融合模型)
在这里设置模型的名字。
③设置Merge比例
传统融合有两种方式,分别为:
加权和Weighted sum:将两个模型权重的加权和作为新模型的权重,仅需要填入模型A和B,公式:A*(1-M) + B*M,倍率(M)为模型B所占比例
加上差值Add difference:将模型B与C的差值添加到模型A,需要同时填入模型A、B和C,公式:A + (B-C)*M,倍率(M)为添加的差值比例
④选择fp16
请直接选择fp16,默认情况下,webui 会将所有加载的模型转换为FP16使用。所以很多时候更高的精度是没啥意义的,不使用--no-half这些模型将完全相同。而实际上哪怕使用--no-half,模型的差别也并不会很大,所以直接选择fp16测试效果即可。
⑤Merge

点击它后等待一会即可,模型在你的webui根目录下的models/Stable-diffusion文件夹。
需要注意的是:传统融合效果并非比现在的mbw等操作效果差
3. Merge Block Weighted
扩展插件: bbc-mc/sdweb-merge-block-weighted-gui
插件基本功能:
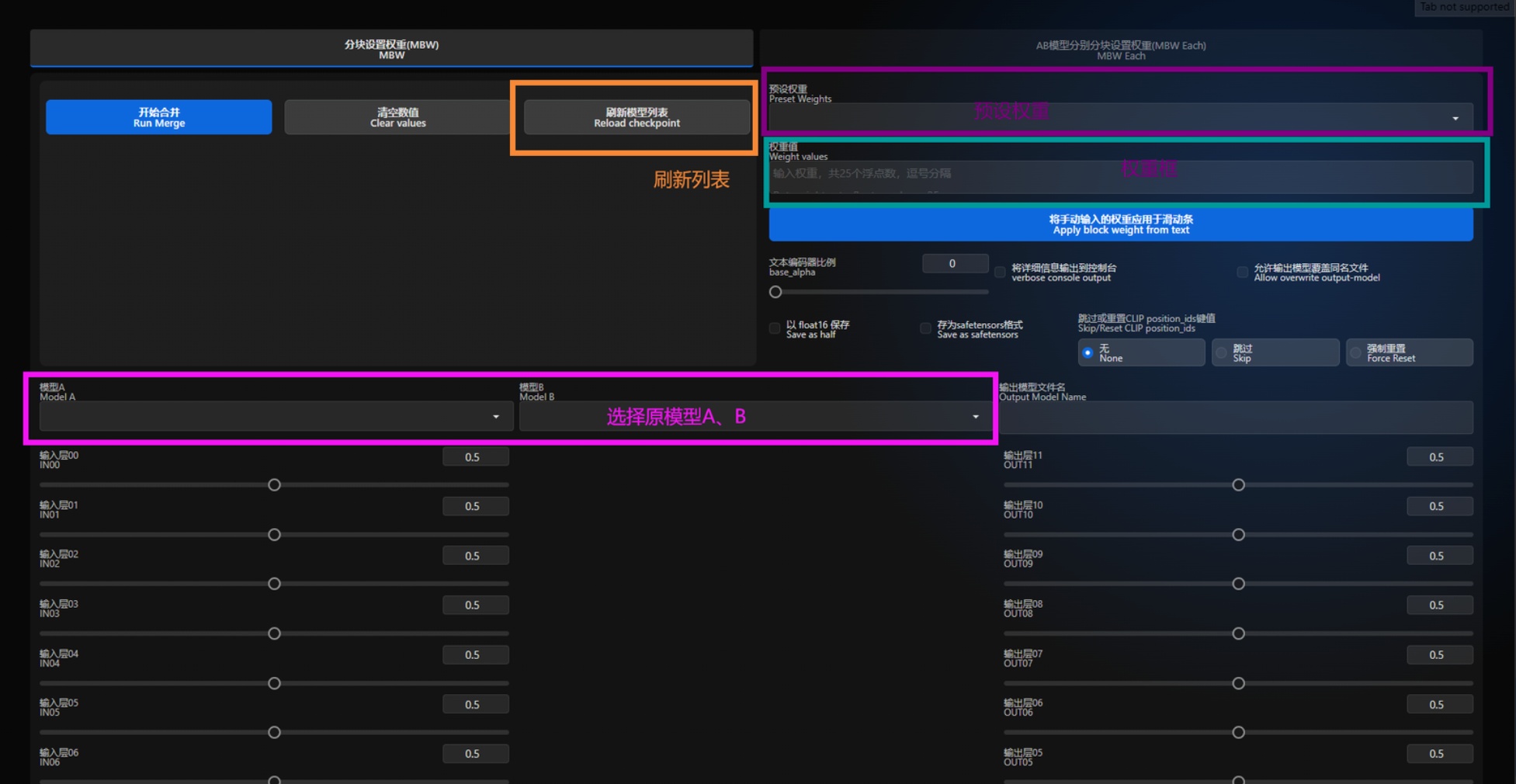
开始合并:点击后直接开始融合
清空数值:将下方的滑条全部置为0.5
刷新模型列表:刷新模型列表。在webui开启状态下,如果模型文件夹新加入了模型,那么将会无法自动识别。如果原模型区域找不到新加入的模型,那么点击这里即可刷新模型列表
模型A:选择需要融合的模型A
模型B:选择需要融合的模型B
输出模型文件名:你要输出的模型文件名称,通常为xxxMix
预设权重:官方预设融合权重,选择后直接加载进下面的滑块
权重框:输入自定义的融合权重,输入完成后点击下面的按钮直接加载进滑块
文本编码器比例:A和B模型的语义分析模块的融合比
跳过或重置CLIP position_ids键值:防止clip偏移导致模型出现各种提示词识别问题,强烈建议选择:强制重置Force Reset
MBE能达到的效果:
画风更换、人体修复、剔除污染层等
更详细的MBW详解:
4. LoRA的注入与提取
扩展插件:hako-mikan/sd-webui-supermerger插件基本功能除了MBW以外还有LoRA处理的相关功能:当然更多进阶的功能可以到插件仓库去查阅README.md,这里不做更详细的讲解。通过两个ckp大模型之间做差可以得到一个LoRA。需要注意的是这里需要在filename(option)这一栏输入想要的名称,不然无法提取
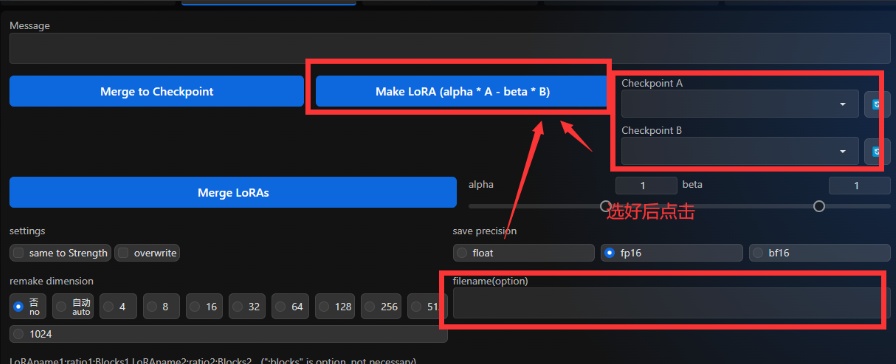
点击下面的LoRA然后在上面选择模型,就可以把LoRA注入到ckp大模型里(同样需要在filename(option)这一栏输入想要的名称,不然无法注入)。需要注意的是,这里只能注入LoRA,并不能操作Loha等一系列其他模型,如有报错请检查模型格式是否正确。
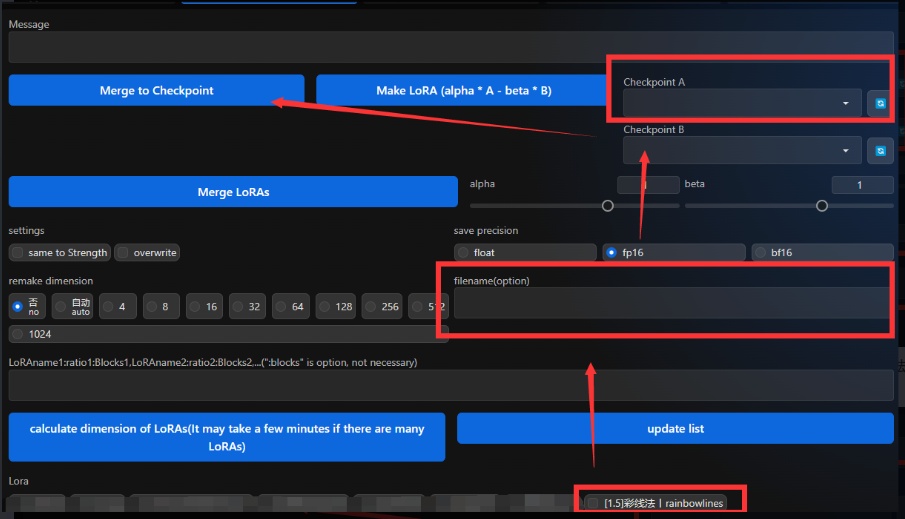
注意:部分模型做差提取LoRA后使用和原ckp模型效果差距很大,部分LoRA注入后和直接使用效果差距也会很大,具体是否可用请根据不同的模型自行测试
5. 灾难性遗忘与模型融合
限制很多模型灾难性遗忘(本来模型会的被炼到不会了)现象较为严重(排除掉lora的一些特定需求 其余的微调大部分层次的训练都可能有这个现象),而模型融合会放大这个现象。(比如模型只能出1girl)
更多的功能,更多的插件,无限的可能
注意:安装扩充功能可能会导致Stable Diffusion WebUI启动变慢,甚至无法启动,并且哪怕使用启动器也无法扫描出异常。
请不要自行下载 DreamBooth的WebUI插件!!!
请不要自行下载 TensorRT 的WebUI插件!!!
请不要自行下载 TemporalKit 的WebUI插件!!!
请不要自行下载 Deforum 的WebUI插件!!!
自行下载这些插件并且炸了的唯一最佳解决方法:完全删除并重装WEBUI
1. 用Webui图形界面安装
①最简单的方法就是点击Extensions → Available的Load from:,就会列出可下载安装的扩充功能,点击安装
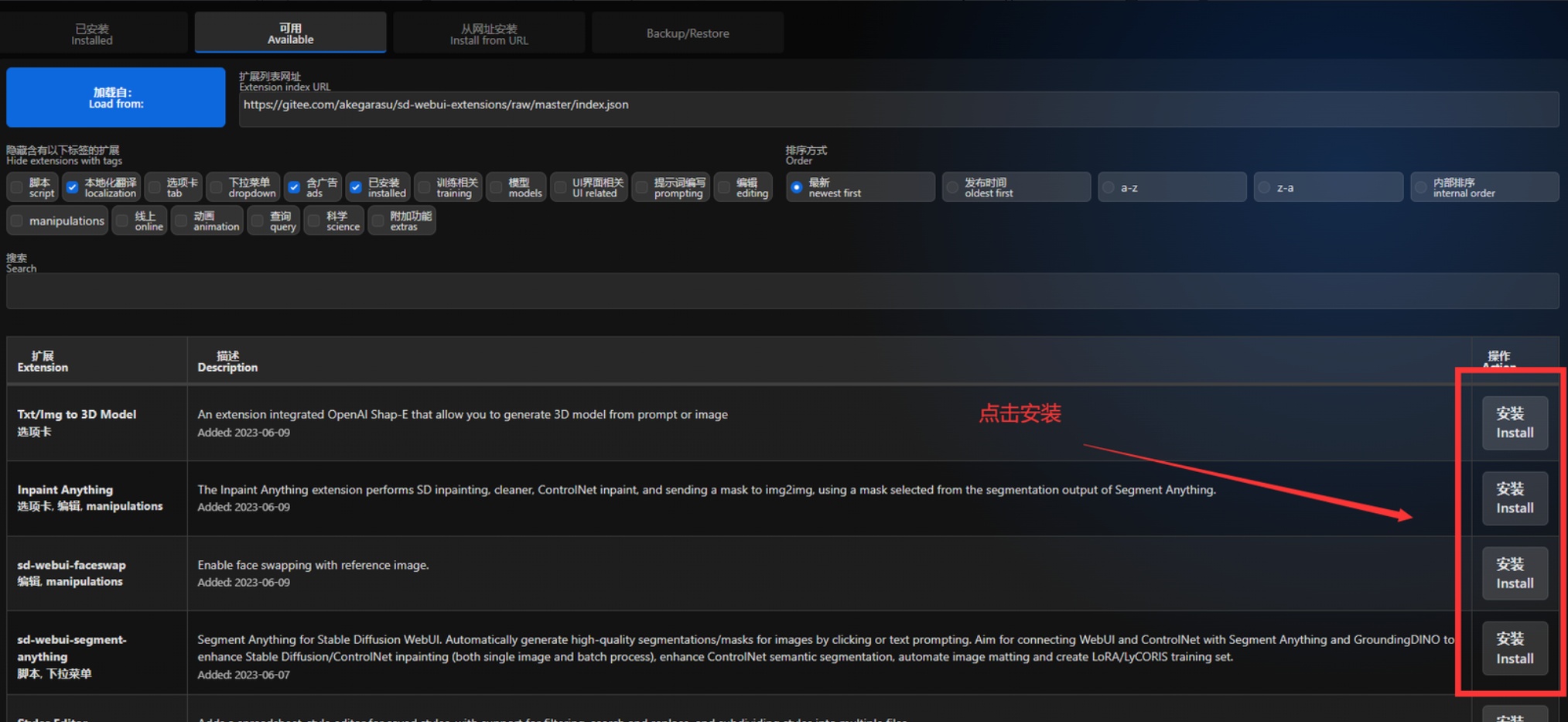
②部分不在列表的插件,需要将Github库链接直接填入WebUI插件下载区,等待自动加载完毕即可
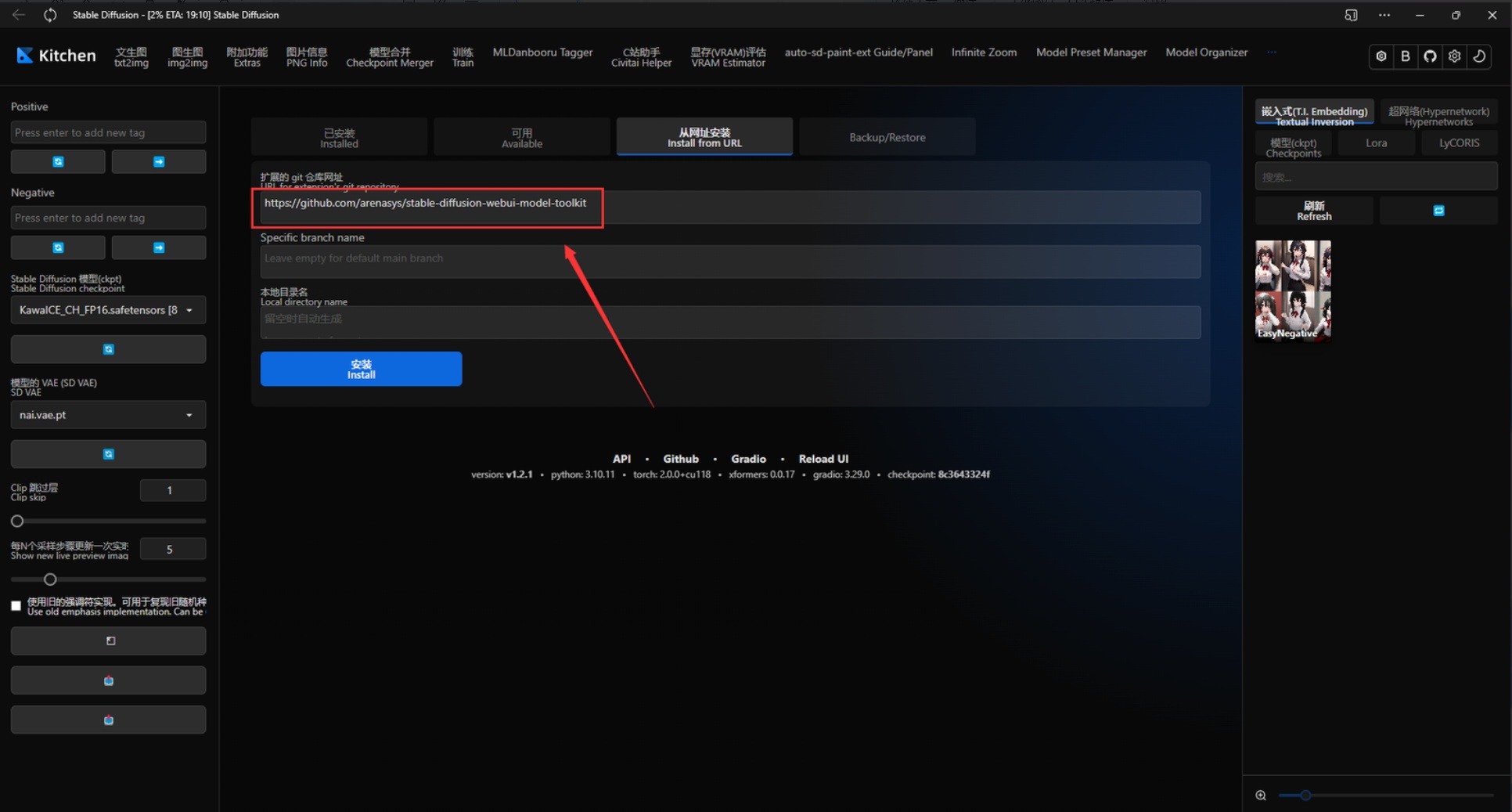
③安装完成后必须点击这里重启UI网页界面(小退)才能使用,有的插件则是需要“大退”,即关闭Webui实例,重新启动。
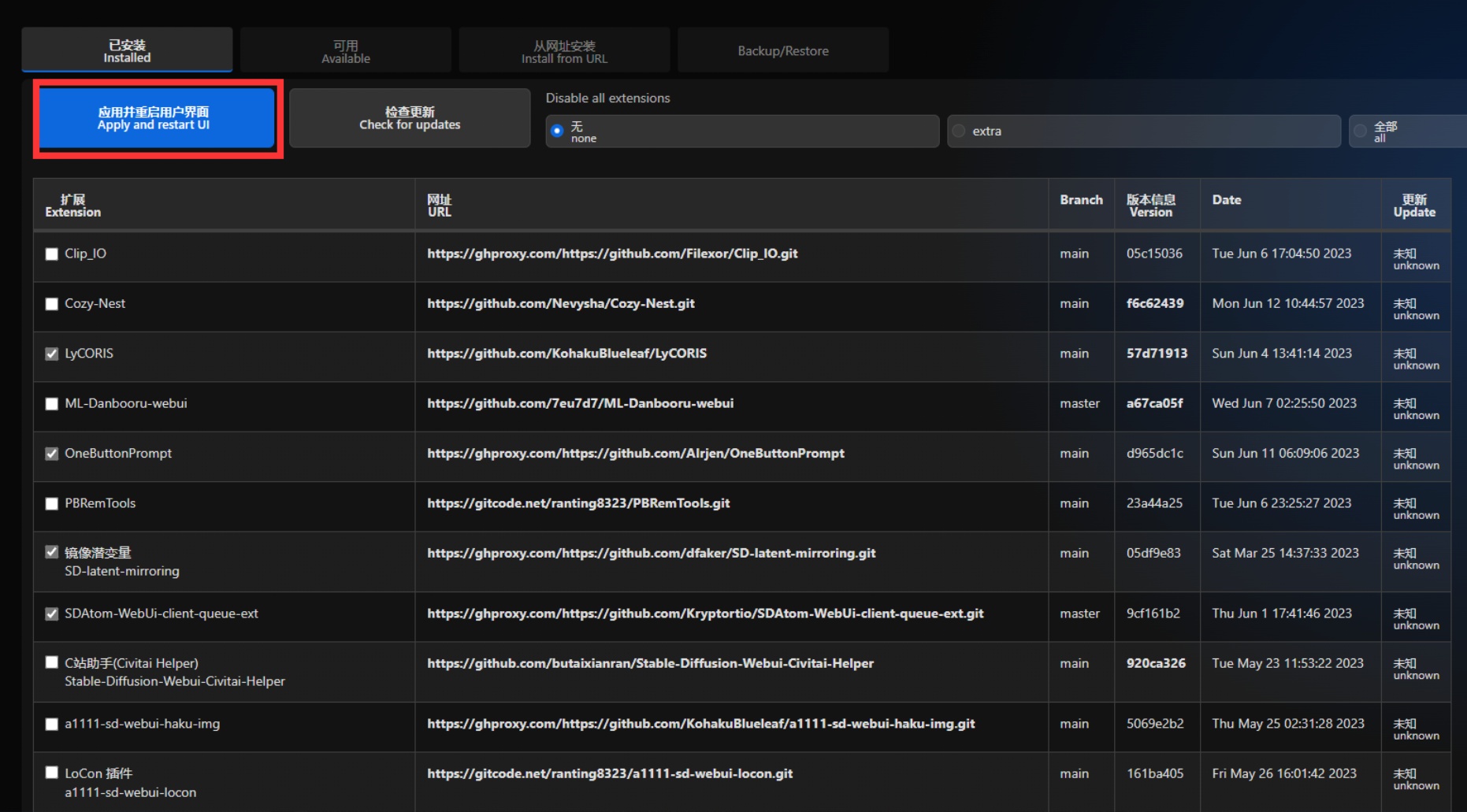
④更新扩展插件推荐使用启动器,而非Webui内的检查更新。webui内的检查更新大概率会卡住。
2. 使用git安装
①(安装前需要关闭你的webui实例)在你的webui根目录/extensions文件夹打开终端,运行git clone指令,安装扩充功能。
例如:
git clone https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111.git②打开WebUI,你就会看到新安装的扩展功能
③windows系统插件更新同样可以使用启动器进行更新
3. 使用压缩包安装
①github界面点击【Download ZIP】
注意:请在尝试了其他安装方式并且均失败的情况下再选择直接下载zip解压
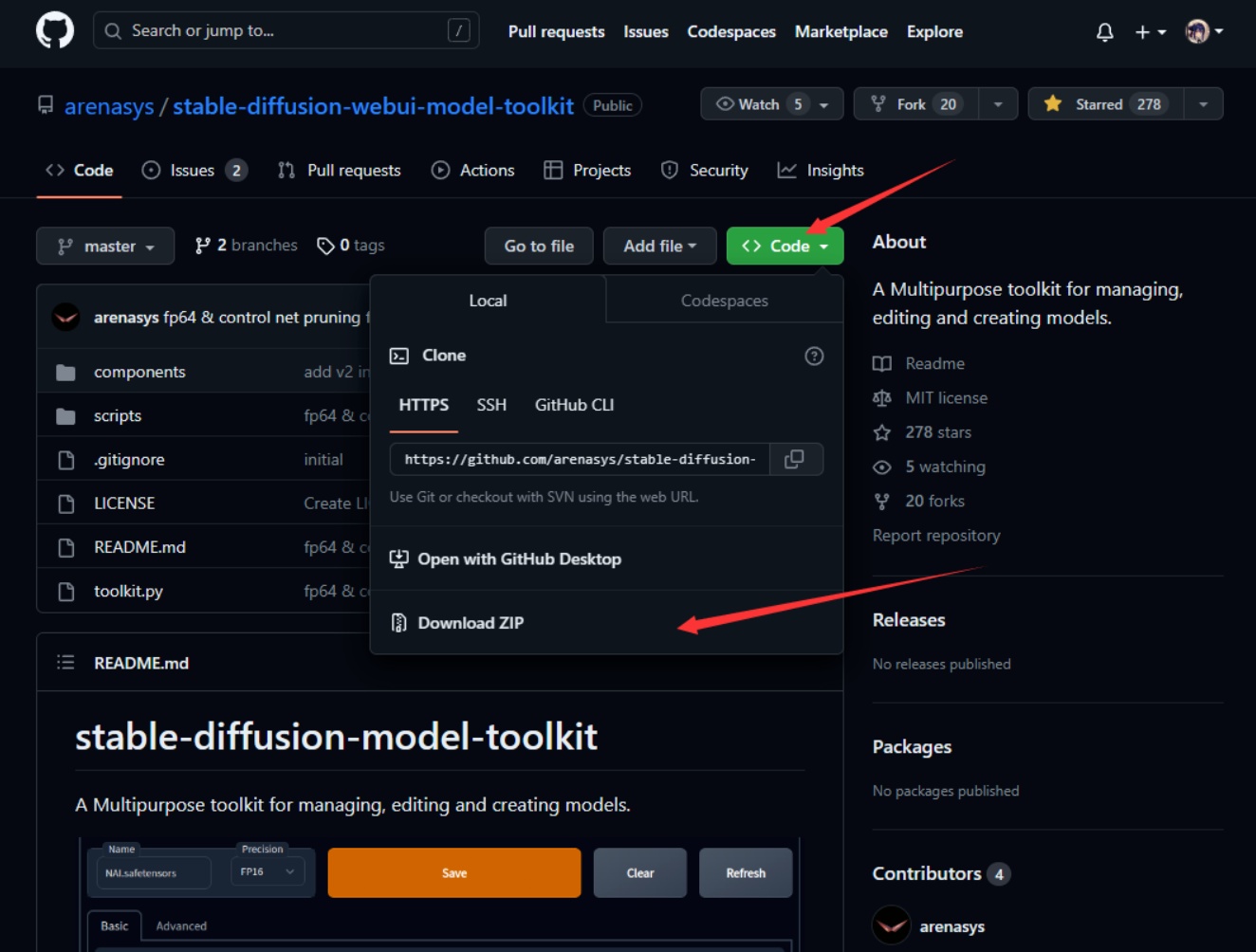
②完整解压后放在扩展文件夹:你的WebUI所在文件夹/extensions(需要关闭你的webui实例)
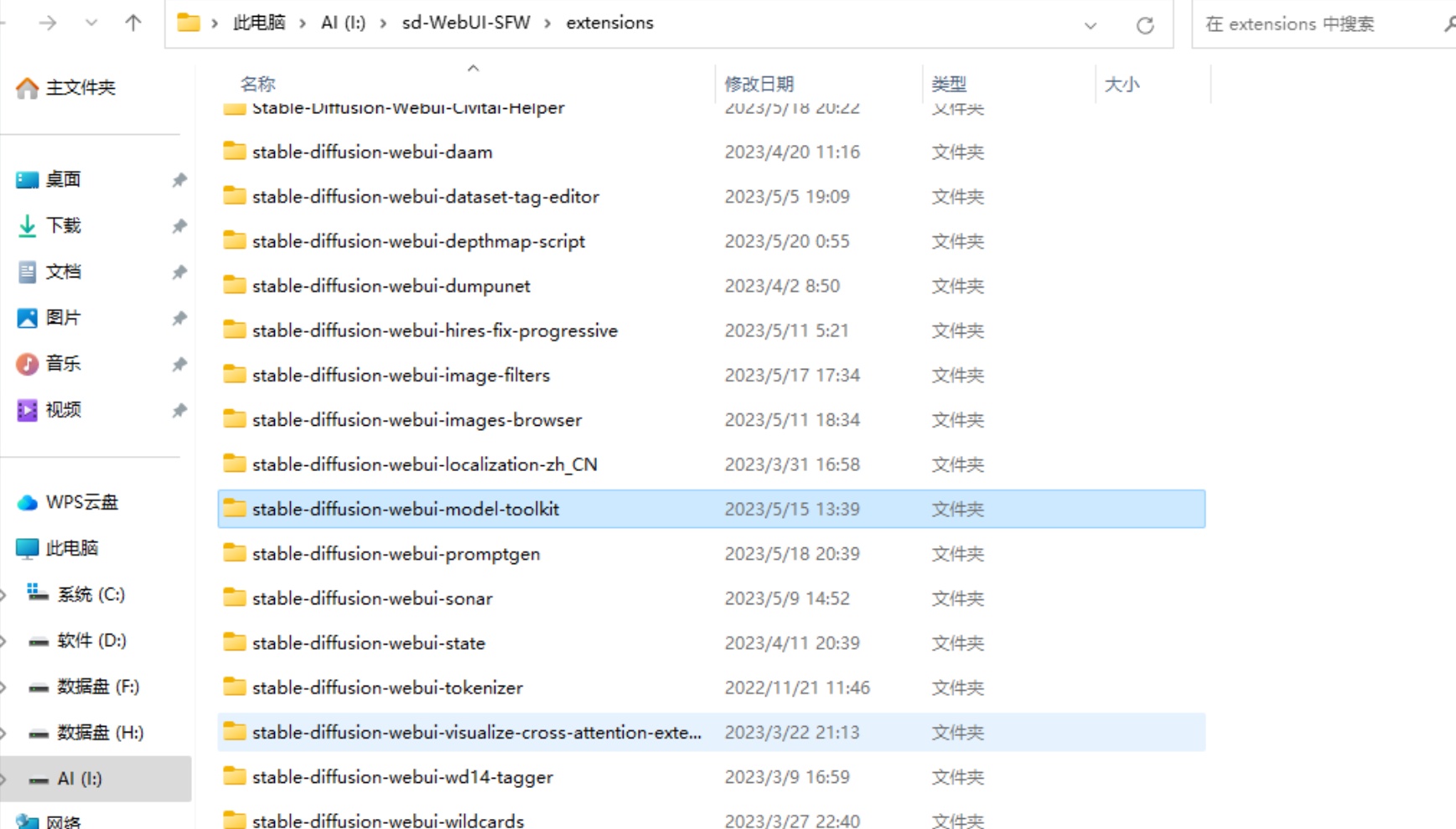
③重新开启webui后能在插件列表中看到即为安装成功
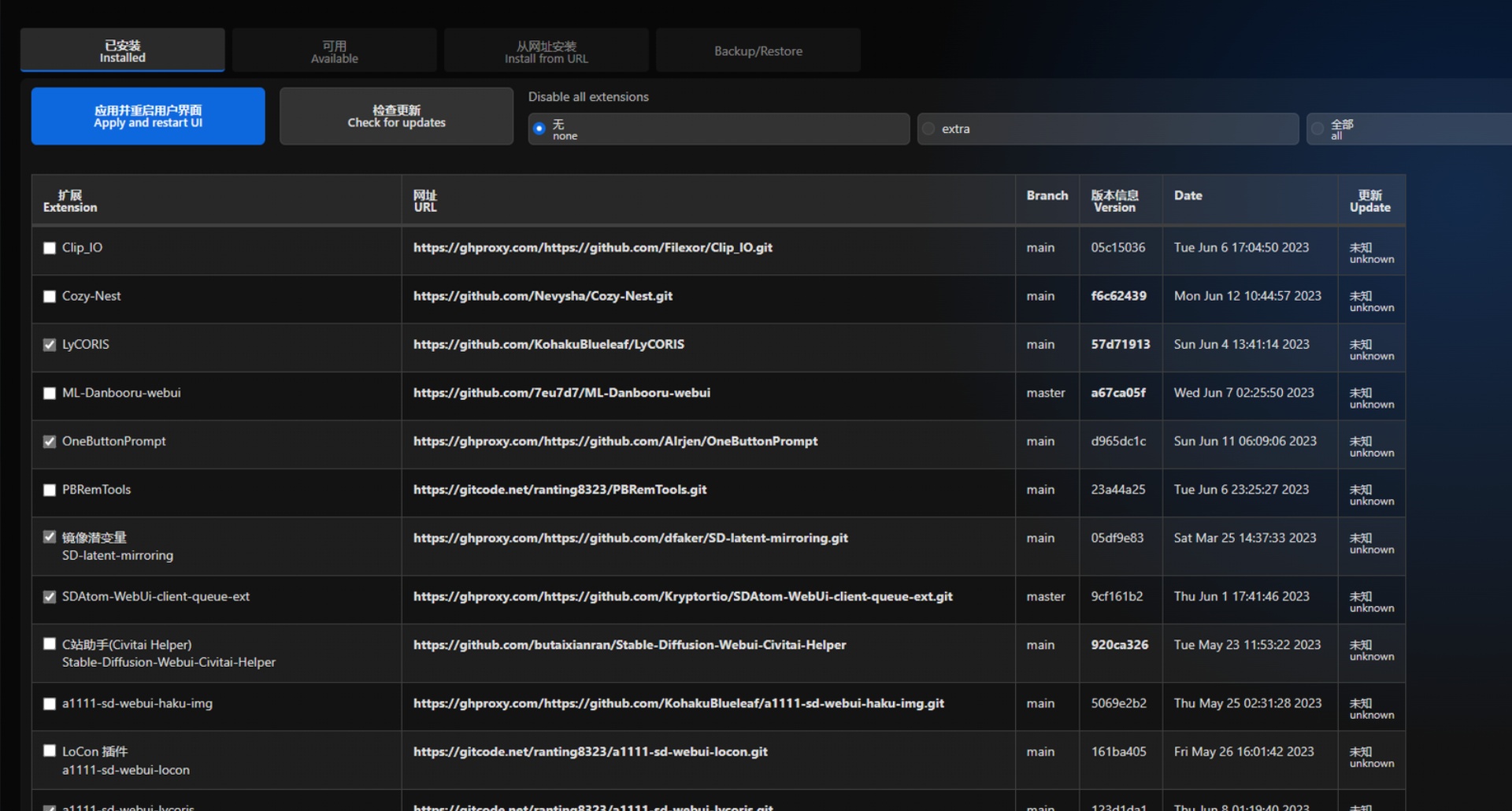
4. 停用、卸载、删除插件
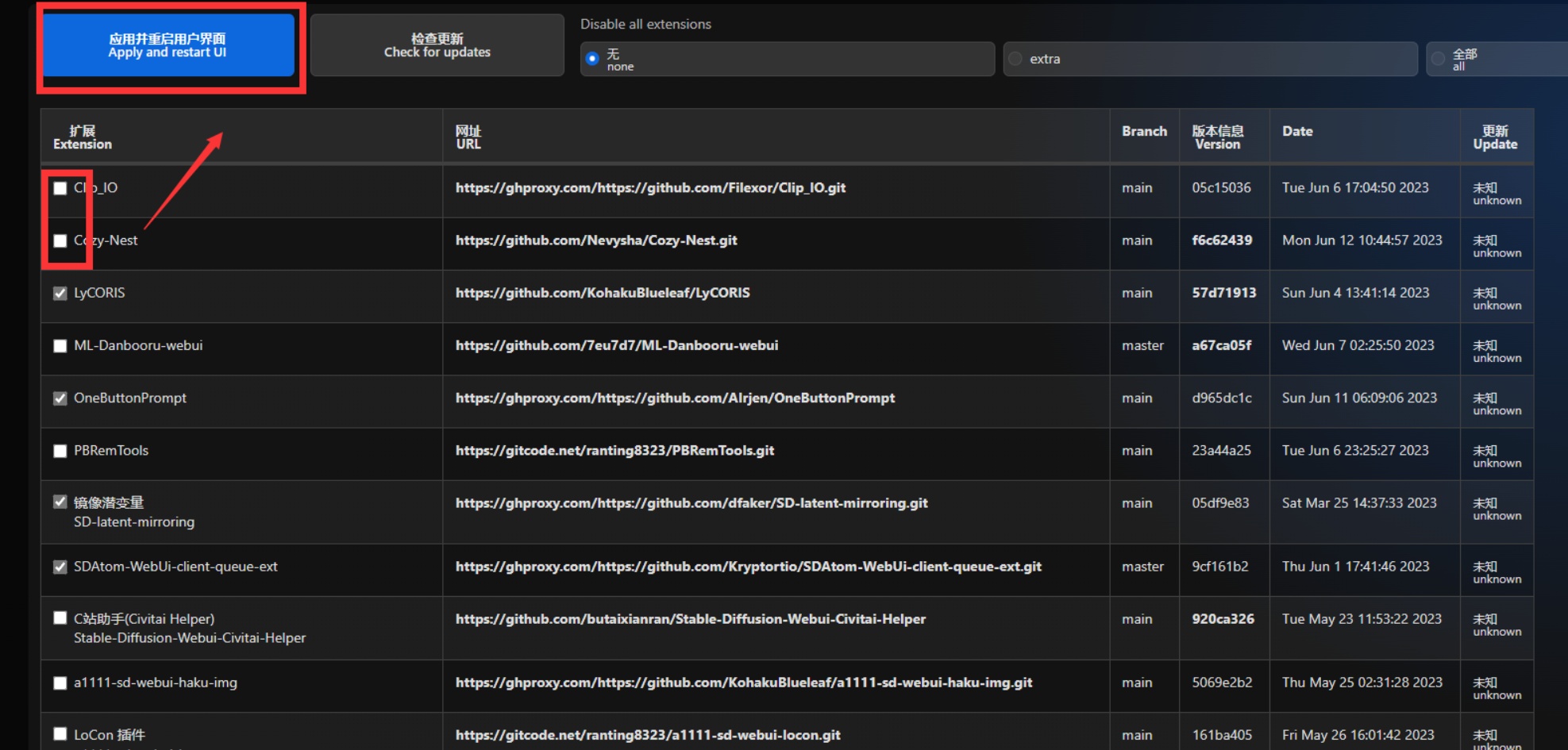
①对于暂时不使用插件,点击扩展前面的✔并且重启用户界面即可
②删除、卸载插件最简单的方法是在启动器界面点卸载(卸载插件前请关闭你的Webui实例)
请远离玄学民科
1. 说明
AI绘画使用的超低门槛与实际研究群体的超高门槛之间存在着非常严重的断层。这就意味着玄学民科的内容会非常的多。
这个文档反驳了非常多的玄学民科内容,然而还有更多的玄学民科内容还在等着我们去科普
2. 现状
SD目前并没有专门的交流社区/或者说即使有交流社区那么环境也是比较差的(例如猫鼠队),而一般的网站又过于简单零碎各自为阵的群聊也有一部分人在输出玄学民科内容,并且还有相当的一部分人进行吹捧。而刚接触的新人也没啥分辨能力,自然而然的会出现,玩了几个月发现自己玩的都是垃圾,或者自己也加入输出这种内容等等情况。
彻底卸载Stable Diffusion Webui
1. 删除环境/软件
python、git等软件都可以在windows系统内设置界面直接卸载,直接打开设置-应用-安装的应用搜索卸载即可
2. 删除Webui本体
直接删除Webui目录文件夹即可。
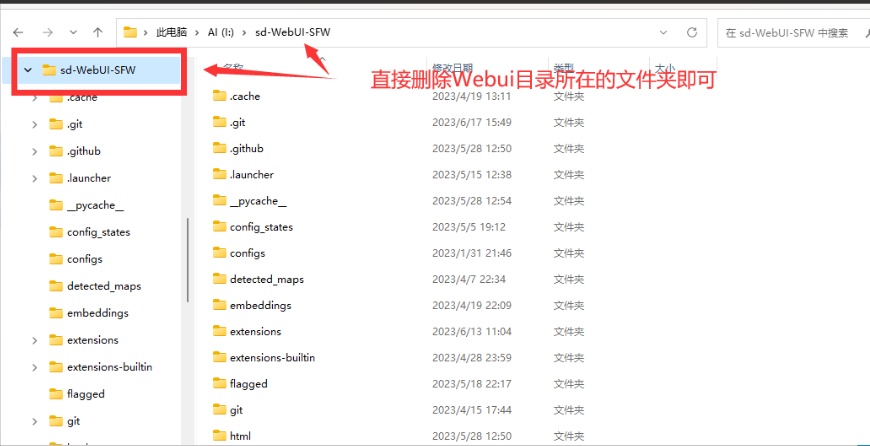
注意这里有一个魔鬼细节:请不要在windows资源管理器内直接右键删除文件夹,如果这样直接删除,那么大概率需要几个小时的时间来检索文件目录。长期使用的stable diffusion Webui本体很可能有几十万个文件,检索相当耗时。
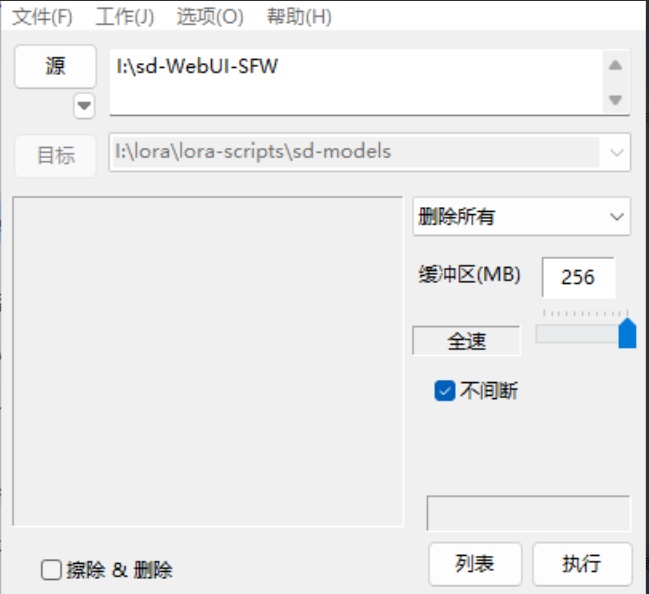
推荐三种方法:
①打开终端使用命令行删除
②使用FastCopy直接删除所有(注意不要点左下角的擦除&删除)
③如果你听了我的建议整个Webui相关的东西都放在了同一个盘符中,那么推荐使用快速格式化,这样删除是最快最方便的。
3. 删除缓存文件
①Webui缓存
C:\Users\你的用户名\.cache
这其中这4个文件夹是Stable Diffusion Webui所创建的缓存文件,只需要删除这四个文件夹就可以了,多出来的文件夹是你安装的许多其他的东西。
②pip下载缓存
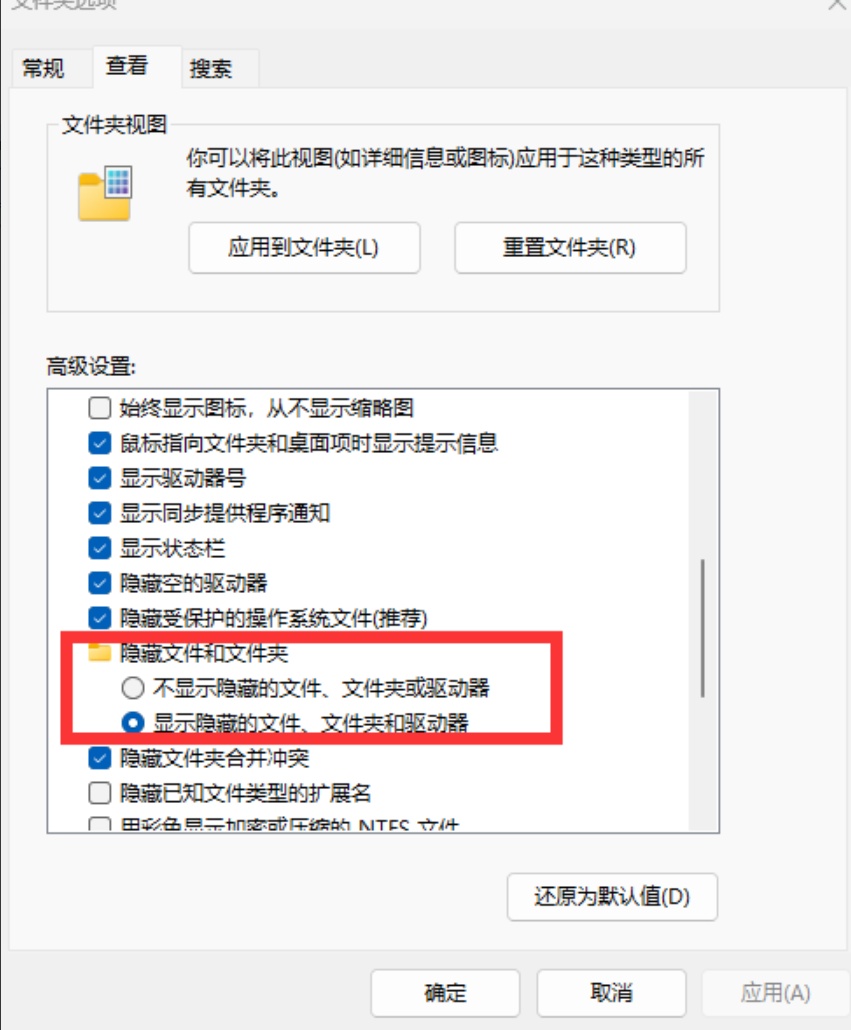
C:\Users\用户名\AppData\Local\pip\cache
如果找不到AppData文件夹那么请修改文件夹选项:隐藏文件和文件夹-显示隐藏的文件、文件夹和驱动器。
cache文件夹可以直接全部删除不会影响其他的东西

Stable diffusion相关词汇表
● artificial intelligence generated content (AIGC): 生成式人工智能
● ancestral sampling: 祖先采样,又称向前采样
● annotation: 标示
● batch count: 批量数量
● batch size: 批量大小
● checkpoint: 存盘点,模型格式,附文件名为.ckpt。
● classifier-free guidance scale (CFG scale): 事前训练的条件控制生成方法。
● CodeFormer: 2022年由Shangchen Zhou等人发表的脸部修复模型。
● conditioning:制约训练
● ControlNet: 2022年由Lvmin Zhang发表,通过加入额外条件来控制扩散模型的神经网络结构。
● cross-attention: 分散注意
● dataset: 数据集
● denoising: 去噪,降噪
● diffusion: 扩散
● Denoising Diffusion Implicit Models (DDIM): 去噪扩散隐式模型,2022年由Jiaming Song等人发表的采样方法。
● Dreambooth: Google Research和波士顿大学于2022年发表的深度学习模型,用于调整现有的文生图模型。
● embedding: 嵌入
● epoch: 时期
● Euler Ancestral (Euler a): 基于k-diffusion的采样方法,使用祖父采样与欧拉方法步数。可在20~30步数生出好结果。
● Euler: 基于k-diffusion的采样方法,使用欧拉方法步数。可在20~30步数生出好结果。
● fine-tune: 微调
● float16 (fp16): 半精度浮点数
● float32 (fp32): 单精度浮点数
● generate:生成图片
● Generative Adversarial Network (GAN):生成对抗网络,让两个神经网络相互博弈的方式进行学习的训练方法。
● GFPGAN: 腾讯于2021年发表的脸部修复模型。
● hypernetwork: 超网络
● image to image: 图生图
● inference: 模型推理
● inpaint: 内补绘制
● interrogator: 图像理解
● k-diffusion: Karras等人于2022年发表的PyTorch扩散模型,基于论文〈Elucidating the Design Space of Diffusion-Based Generative Models〉所实作。
● latent diffusion: 潜在扩散
● latent space: 潜在空间
● learning rate: 学习率
● Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion (LyCORIS)
● low-rank adaptation (LoRA): 低秩自适应,2023年由Microsoft发表,用于微调大模型的技术。
● machine learning: 机器学习
● model:模型
● negative prompts: 负向提示词
● outpaint: 外补绘制
● pickle: 保存张量的模型格式,附文件名为.pt
● postprocessing: 后处理
● precision: 精度
● preprocessing: 预处理
● prompts: 提示词
● PyTorch: 一款开源机器学习库
● safetensors: 由Huggingface研发,安全保存张量的模型格式。
● sampling method: 采样方法
● sampling steps: 采样步数
● scheduler: 调度器
● seed: 种子码
● Stable Diffusion: 稳定扩散,一个文生图模型,2022年由CompVis发表,由U-Net、VAE、Text Encoder三者组成。
● text encoder: 文本编码
● text to image: 文本生成图片,文生图
● textual inversion: 文本倒置
● tiling: 平铺
● token: 词元
● tokenizer: 标记解析器
● Transformers: HuggingFace研发的一系列API,用于辅助PyTorch、TensorFlow、JAX机器学习,可下载最新预训练的模型。
● U-Net:用于影像分割的卷积神经网络
● unified predictor-corrector (UniPC): 统一预测校正,2023年发表的新采样方法。
● upscale: 升频,放大
● variational auto encoder (VAE): 变分自动编码器
● weights: 权重
● xFormers: 2022年由Meta发表,用于加速Transformers,并减少VRAM占用的技术。