











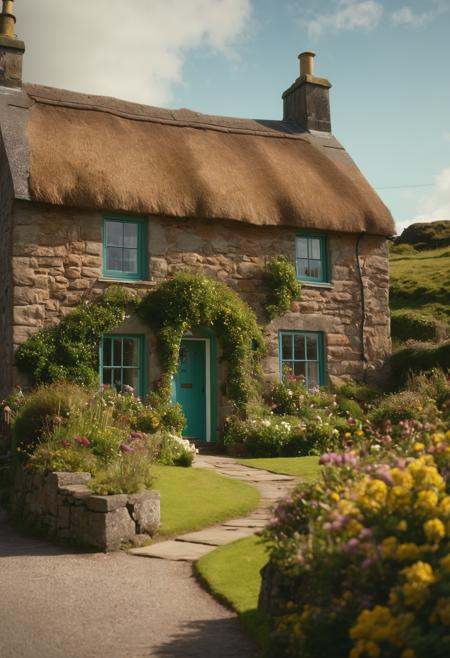








For business inquires, commercial licensing, custom models, and consultation contact me under juggernaut@rundiffusion.com
Juggernaut is available on the new Auto1111 Forge on RunDiffusion
JuggernautXL V9 + RunDiffusion Photo 2 on Hugging Face
A big thanks for Version 9 goes to RunDiffusion (Photo Model) and Adam, who diligently helped me test :) (Leave some love for them ;) )
It's time for another round, this time a bit delayed, but I hope you forgive the delay. Let's dive straight into the changes that await you or what we've been working on lately:
For V9, I myself have only done basic training. This involves some work on skin details, lighting, and overall contrast. However, the biggest change to the model came from the RunDiffusion Photo Model update, which was made available to me in V2 by RunDiffusion. The photographic output of the model should, in our experience, be even stronger than in previous versions.
Now for a small "roadmap" update, or a general status update on how things are progressing with Juggernaut. As you may have noticed, there was a slight delay with V9. With each successive version, it has become increasingly difficult to train Juggernaut without sacrificing quality in some areas, which was already the case to some extent with V8. Don't worry, V9 is really good, and I'm satisfied with the version I can present to you today :) However, I've decided to go for a complete "reboot" for V10. I want to simply retrain the Juggernaut base set. The conditions for better captioning weren't as favorable "back then" as they are today, so I want to completely re-caption the base set (5k images) with GPT-4 Vision. I expect a big leap towards prompting guidance and quality.
But as you surely noticed last week, the release of Stable Cascade got in the way a bit. Therefore, my focus in the coming weeks will be on training Juggernaut for Stable Cascade. The approach remains the same as with the planned "reboot"; I want to caption/tag all images in the future only with GPT-4 or manually. The timeline for all of this is still uncertain. I hope to be able to present you with a first stable version of Juggernaut Cascade sometime in March. V10 of Juggernaut XL will follow in the weeks thereafter.
Now, here are some additional tips to make prompting easier for you:
Res: 832*1216
Sampler: DPM++ 2M Karras
Steps: 30-40
CFG: 3-7 (less is a bit more realistic)
Negative: Start with no negative, and add afterwards the Stuff you don´t wanna see in that image. I don´t recommend using my Negative Prompt, i simply use it because i am lazy :D
VAE is already Baked In
HiRes: 4xNMKD-Siax_200k with 15 Steps and 0.3 Denoise + 1.5 Upscale
And a few keywords/tokens that I regularly use in training, which might help you achieve the optimal result from the version:
Architecture Photography
Wildlife Photography
Car Photography
Food Photography
Interior Photography
Landscape Photography
Hyperdetailed Photography
Cinematic
Movie Still
Mid Shot Photo
Full Body Photo
Skin Details
And now, have fun trying it out. As always, I'm eagerly waiting for your pictures in the Gallery :)
If you liked the model, please leave a review. In the end, that's what helps me the most as a creator on CivitAI. :)
Last but not least, I'd like to thank a few people without whom Juggernaut XL probably wouldn't have come to fruition:
Dreamlook.AI (Trained 3 Side Sets)
Chillpixel
SilasAI6609
Adam
Hide