



f. InstantX
● InstantID
InstantID 是由InstantX项目组推出的一种SOTA的tuning-free方法,只需单个图像即可实现 ID 保留生成,并支持各种下游任务。仅上传一张照片,选择风格,即可生成个性化写真
- 网页:InstantID
- 论文:[2401.07519] InstantID: Zero-shot Identity-Preserving Generation in Seconds (arxiv.org)
- 代码:InstantID/InstantID: InstantID : Zero-shot Identity-Preserving Generation in Seconds 🔥 (github.com)
- HF Demo:InstantID - a Hugging Face Space by InstantX
- MS Demo:InstantID · 创空间 (modelscope.cn)
- 整理:diffusion model(十一) InstantID技术小结 - 知乎 (zhihu.com)
- 本地部署教程①:2024最新换脸技术盘点,InstantID封神(附WebUI手把手部署操作攻略) - 知乎 (zhihu.com)
- 本地部署教程②:InstantID大火,你装的上吗?(webui版本) - 知乎 (zhihu.com)
● InstantIStyle
InstantIStyle是InstantID原班人马推出。它是一个通用的,小而美的风格迁移框架,包含两种非常简单而有效的方式来实现参考图像中风格和内容的解耦。
- 网页;InstantStyle
- 代码:InstantStyle/InstantStyle (github.com)
g. IP-Adapter
● IP-Adapter
IP-Adapter是一个轻量而有效的适配器,可为预训练的文本到图像扩散模型提供图像prompt功能。IP-Adapter的核心是通过一种解耦的交叉注意力策略,把图像特征引入到了独立的交叉注意力层,使得图像提示能与文本提示协同工作,在ID保持的人像生成方面效果非常不错。
- 网站:IP Adapter的 --- IP-Adapter
- 代码:GitHub - tencent-ailab/IP-Adapter
- HF:h94/IP-Adapter · Hugging Face
- 解析:保持ID的人像生成技术介绍:IP-Adaptor,PhotoMaker,InstantID - 知乎 (zhihu.com)
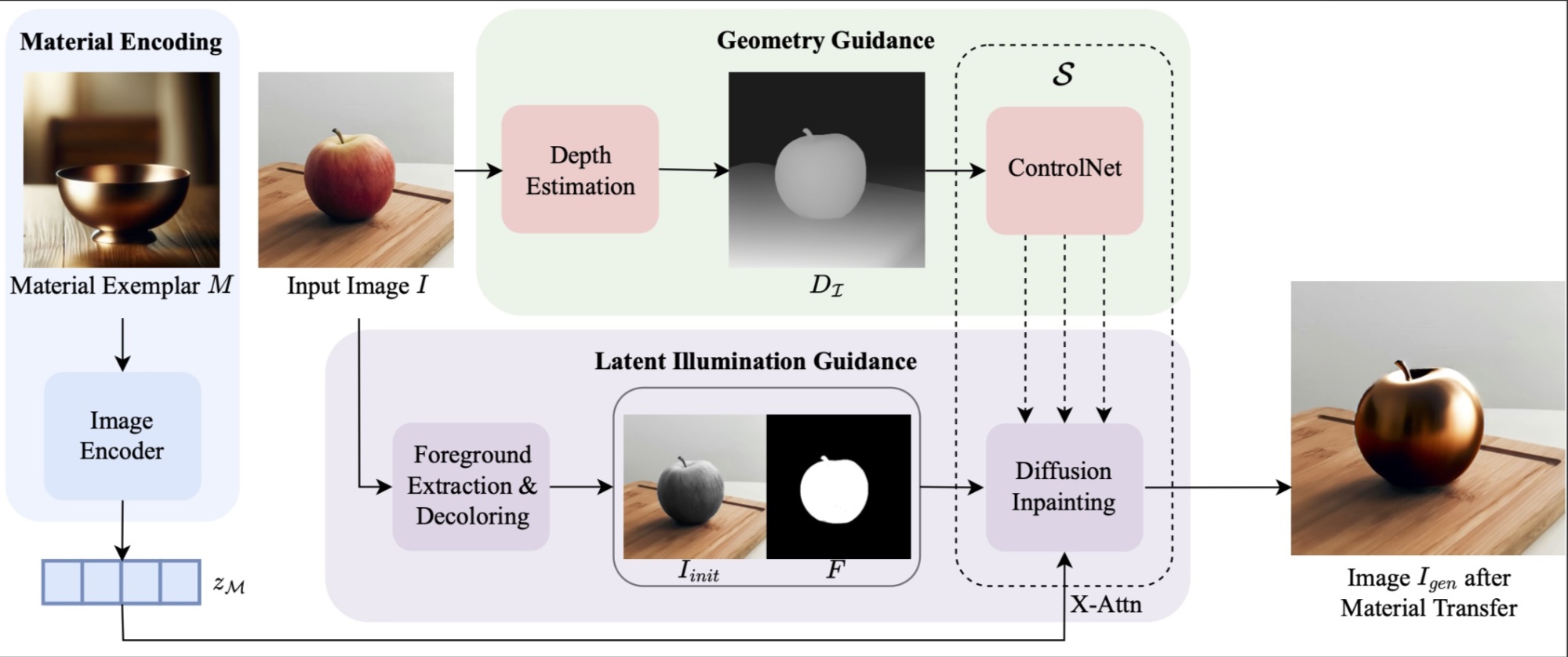
● ZeST
- 网站:Zero-Shot Material Transfer (ttchengab.github.io)
- 论文:[2404.06425] ZeST: Zero-Shot Material Transfer from a Single Image (arxiv.org)
- 代码:GitHub - ttchengab/zest_code: This is the official implementation of ZeST
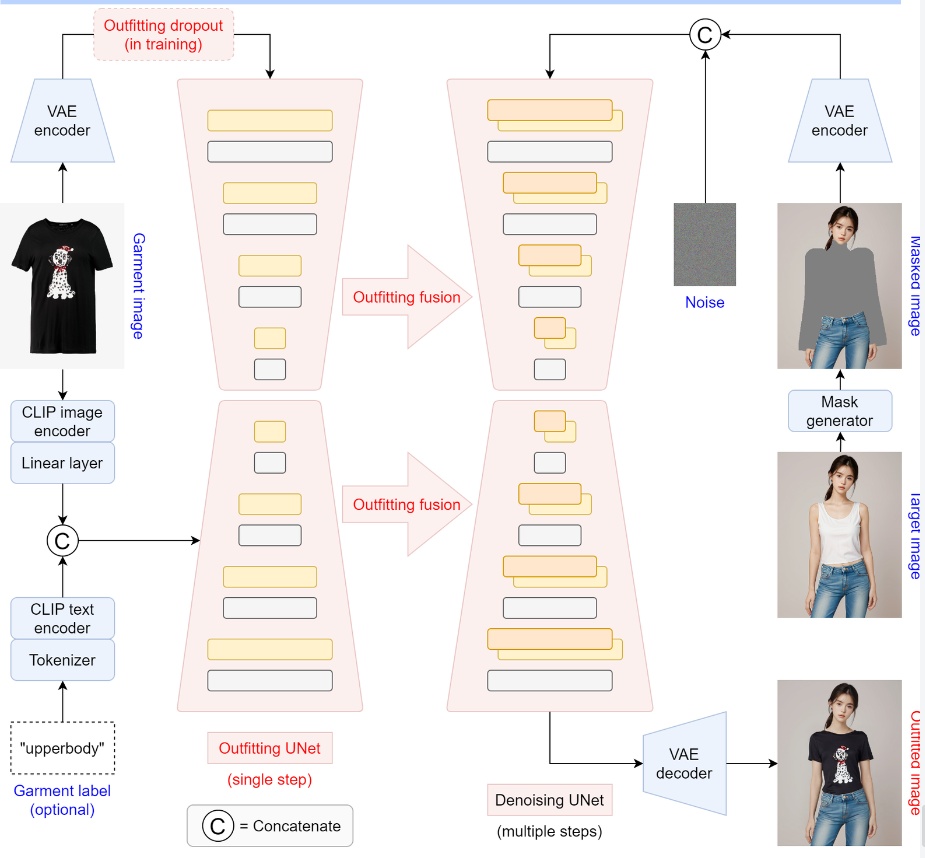
h. OOTDiffusion
OOTDiffusion是一个高度可控的虚拟服装试穿AI工具,它利用潜在扩散模型(latent diffusion model)的先进技术,实现了高质量的服装图像生成和融合。这个工具可以根据用户的性别和体型自动调整服装,确保试穿效果与模特身形贴合,同时用户也可以根据自己的需求和偏好进行调整。
● OOTD
- 代码:levihsu/OOTDiffusion: Official implementation of OOTDiffusion
- HF Demo:OOTDiffusion - a Hugging Face Space by levihsu
- 模型:levihsu/OOTDiffusion · Hugging Face
● MagicClothing
- HF:ShineChen1024/MagicClothing · Hugging Face
- 论文:[2404.09512] Magic Clothing: Controllable Garment-Driven Image Synthesis (arxiv.org)
- Comfy节点:frankchieng/ComfyUI_MagicClothing: unofficial implementation of Comfyui magic clothing (github.com)
13. 视频声音 | AI除了画画之外……
AI动画、声音相关的内容,工具书作者仅仅是尝试过,并没有深度研究使用,只是有人补充才添加到这里的。a. AI 动画(视频)
● Stable Video Diffusion
- 网站:Introducing Stable Video Diffusion — Stability AI
- git仓库:Stability-AI/generative-models: Generative Models by Stability AI (github.com)
- HF:stabilityai/stable-video-diffusion-img2vid-xt · Hugging Face
- 论文解读:【Stable Video Diffusion论文】视频生成SD,Stability AI又一开源力作_哔哩哔哩_bilibili
其他相关内容
- FizzleDorf's Animation Guide (rentry.org)
- FizzleDorf's Animation Guide - Deforum (rentry.org)
- Stable Diffusion Loopback Wave Script (rentry.org)
视频相关生成扩展
- deforum:https://github.com/deforum-art/deforum-for-automatic1111-webui
- T2V:https://github.com/deforum-art/sd-webui-modelscope-text2video
● AnimateDiff
- git仓库:guoyww/AnimateDiff: Official implementation of AnimateDiff. (github.com)
- 网站:AnimateDiff
- HF spaces:AnimateDiff - a Hugging Face Space by guoyww
- motion lora:AnimateDiff Motion LoRAs - Zoom In | Stable Diffusion LoRA | Civitai
快捷生成GIF(AnimateDiff for webUI):
● Magic Animate(字节)
- 视频:【单图生成动画一键安装包】字节最新技术Magic Animate本地windows尝鲜版_哔哩哔哩_bilibili
- git 仓库: sdbds/magic-animate-for-windows: MagicAnimate
- 网站:MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model (showlab.github.io)
- Hf demo:MagicAnimate - a Hugging Face Space by zcxu-eric
● Animate Anyone(阿里)
- 网站:Animate Anyone (humanaigc.github.io)
- git仓库:HumanAIGC/AnimateAnyone
摩尔线程开源版本AnimateAnyone
- git仓库:GitHub - MooreThreads/Moore-AnimateAnyone
- 一键包:【单图生成动画一键安装包】摩尔线程开源最新技术AnimateAnyone本地windows尝鲜版_哔哩哔哩_bilibili
通过通义千问体验Animate Anyone
- 秋叶动态:秋葉aaaki的动态-哔哩哔哩 (bilibili.com)
- 通义千问:通义千问 (aliyun.com)
● VideoCrafter(腾讯)
- 介绍文档:VideoCrafter2:腾讯开源新的AI视频生成模型,可下载模型后离线体验 (qq.com)
- 项目主页:VideoCrafter2 (ailab-cvc.github.io)
- 模型(HF):VideoCrafter/VideoCrafter2 at main (huggingface.co)
- HF Demo:VideoCrafter Demo - a Hugging Face Space by VideoCrafter
b. AI 声音
人声提取工具:
- b站链接:最强伴奏人声提取工具 - 开源免费,一键安装,直接使用!| Ultimate Vocal Remover | UVR5_哔哩哔哩_bilibili
● AI音乐
- Audioldm Text To Audio Generation - a Hugging Face Space by haoheliu
文生乐
- 网站:Noise2Music (google-research.github.io)
- 论文:[2302.03917] Noise2Music: Text-conditioned Music Generation with Diffusion Models (arxiv.org)
● AI语音相关内容:
Vits:
- Vits2(非官方实现):p0p4k/vits2_pytorch: unofficial vits2-TTS implementation in pytorch (github.com)
Diffsinger
- 论文:[2105.02446] DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (arxiv.org)
- Diff-SVC:prophesier/diff-svc: Singing Voice Conversion via diffusion model (github.com)
- DDSP-SVCyxlllc/DDSP-SVC: Real-time end-to-end singing voice conversion system based on DDSP
Bert-VITS2(群友项目)
- Bert-VITS2 git仓库:fishaudio/Bert-VITS2: vits2 backbone with multilingual-bert (github.com)
- BertVits UI:jiangyuxiaoxiao/Bert-VITS2-UI: BertVITS2前端界面 (github.com)
- 项目视频:爆杀原版?基于Bert-VITS2的原神+崩铁全角色文本转语音实现_哔哩哔哩_bilibili
- 一键整合:【Bert-VITS2-2.1】本地三语标注可视化一键训练整合包_哔哩哔哩_bilibili
这是有人做好的一些模型效果,简易使用也可以用这个
- 简易的AI语音生成合集:AI在线一键语音生成合集 · 创空间 (modelscope.cn)
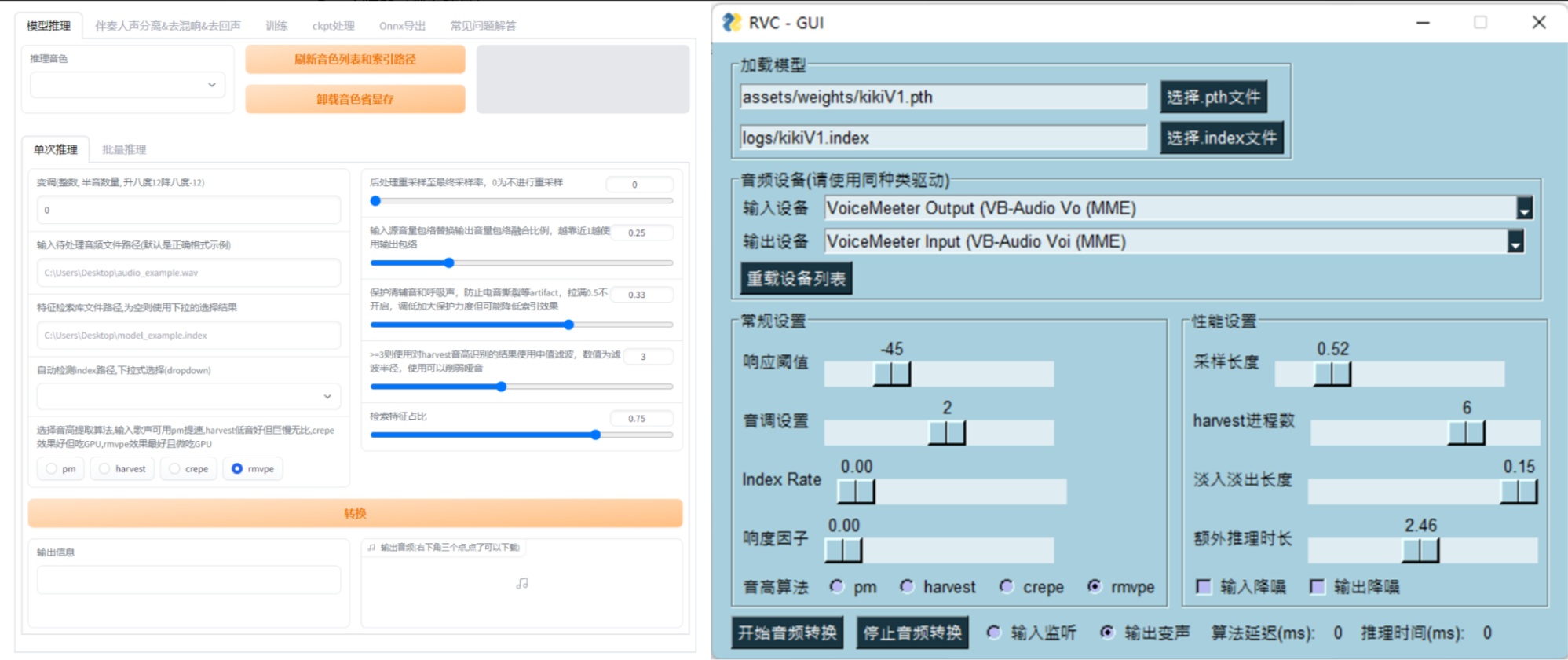
RVC(RVC变声器)
- git项目地址:RVC-Project/Retrieval-based-Voice-Conversion-WebUI
- 官方教程视频:RVC变声器官方教程:10分钟克隆你的声音!一键训练,低配显卡用户福音!_哔哩哔哩_bilibili
So-Vits-Svc
- git仓库:svc-develop-team/so-vits-svc: SoftVC VITS Singing Voice Conversion (github.com)
- 一键包:【AI翻唱/整合包】完美消除哑音!SoVITS 4.0阶段性更新 | 超实用新功能已同步更新至一键包_哔哩哔哩_bilibili
VITS Fast Fine-tuning
- b站视频:【VITS一键包】本地训练独属于你的AI嘴替?训练部署AI语音合成教程_哔哩哔哩_bilibili
- 整合包下载链接:https://pan.baidu.com/s/1NXtnf8q6i_03SXg_t1XOEA?pwd=a24g
- git仓库:https://github.com/Plachtaa/VITS-fast-fine-tuning
tts-vue
- git仓库:LokerL/tts-vue: 🎤 微软语音合成工具,使用 Electron + Vue + ElementPlus + Vite 构建。 (github.com)
tortoise-tts
- tortoise-ttsneonbjb/tortoise-tts: A multi-voice TTS system trained with an emphasis on quality (github.com)
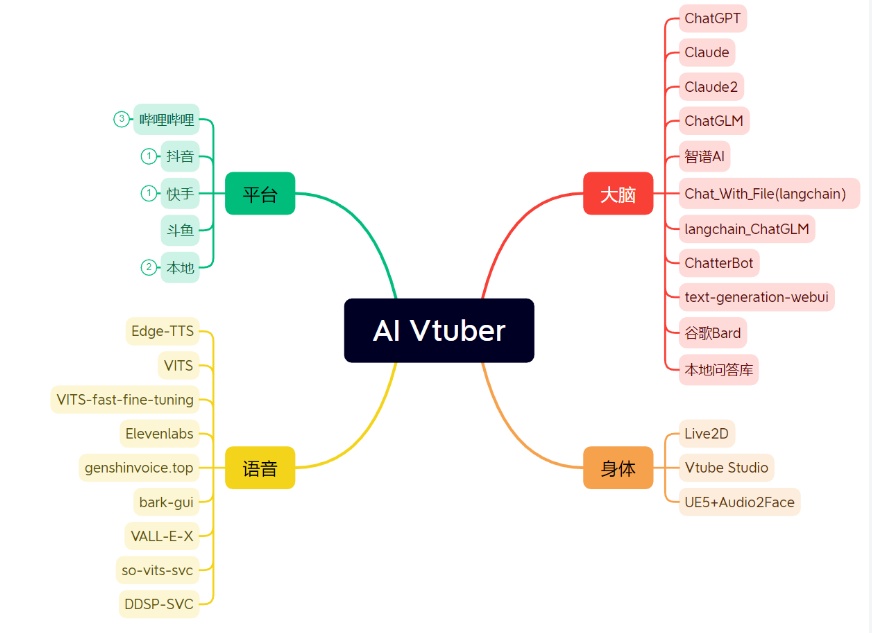
c. AI VTB
● AI立绘法(AI VUPportrait)
使用SD制作AI立绘的工作流:
EasyVtuber AI面捕:
- git仓库:yuyuyzl/EasyVtuber: tha3, but run 40fps on 3080 with virtural webcam support (github.com)
- 教程/展示视频:一键部署,专治精神内耗!不画画不建模,四步就能实现皮套自由?(新安装教程)【EasyVtuber】
● AI Vtuber全套
- luna-ai:Aiyu-awa/luna-ai: Luna AI - 全自动的 AI 直播系统 (github.com)
- AI-Vtuber:Ikaros-521/AI-Vtuber
- 视频教程合集:Love丶伊卡洛斯的个人空间-合集·AI主播-哔哩哔哩视频 (bilibili.com)
- 官方文档:Luna AI (ie.cx)
14. 论文合集 | 未整理未归档AIGC论文/文档等合计
● 相关内容:
文章来自:AIGC图像和视频生成技术研究 By:笑书神侠
另外的合集:AIGC-扩散模型-前沿算法连载 By:曾天真
AI相关论文推荐:AIGC相关论文推荐
AIGC基础知识简介:AIGC基础知识简介:大模型、多模态、预训练、扩散模型
● Diffusion Personalization Methods系列文章总结
Diffusion Personalization Methods系列文章总结
● 加速算法:
扩散模型蒸馏:扩散模型算法加速之一:扩散模型蒸馏 - 知乎 (zhihu.com)
模型量化:扩散模型算法加速之二:模型量化 - 知乎 (zhihu.com)
● Transformer扩散模型相关
解读:深入解读Transformer扩散模型的先驱之作:DiT、PixArt、HDiT
DiT: Scalable Diffusion Models with Transformers, ICCV 2023 Oral
论文:arxiv.org/pdf/2212.09748.pdf
PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis, ICLR 2024
论文:arxiv.org/pdf/2310.00426.pdf
HDiT: Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass Diffusion Transformers, arxiv202401
论文:arxiv.org/pdf/2401.11605.pdf
代码:crowsonkb/k-diffusion: Karras et al. (2022) diffusion models for PyTorch (github.com)
15. 前沿探索 | 我都没见过的东西这破书能有?
建议去arXiv看论文,Github翻翻新代码,或者其他啥的途径看看。
另外可以b站关注沐神(跟李沐学AI)何神(Rayman小何同学)或者看看秋叶青龙(秋葉aaaki、青龙圣者)动态的新玩意也行。
16. AI生成图片著作权侵权第一案判决书
详情如下:
- 判决书:AI生成图片著作权侵权第一案判决书 (qq.com)
- 视频说明:国内AI绘画著作权第一案➡️判决已出_哔哩哔哩_bilibili