



5. 加速优化 | 提高你生图的效率与质量!
a. TensorRT 【特别推荐】
NVIDIA官方发布的 Stable Diffusion Web UI 的TensorRT 加速插件,可将 GeForce RTX 性能提升至高达2倍(实测在文档作者本人的设备上提升3倍左右,下图是在作者本人设备上跑SDXL的大图的速度),TensorRT能大幅提升SD图像的生成速度,且完全不损失质量,目前TensorRT已经支持LoRA和ControlNet。
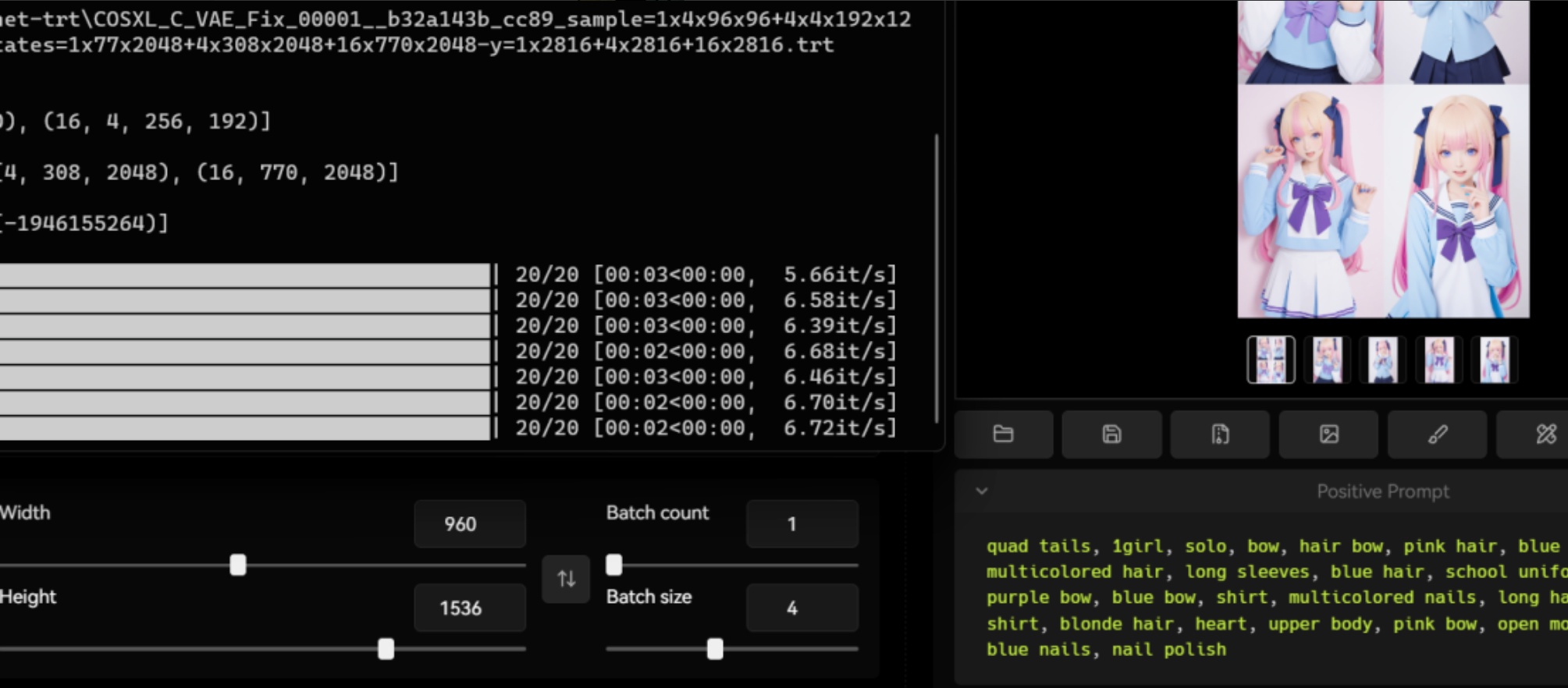
- 使用教程:在Webui上使用TensorRT(教程已经过时,很多东西现在都可以自定义了)
- git仓库:AUTOMATIC1111/stable-diffusion-webui-tensorrt
- 网站:TensorRT SDK 开发工具包
- 安装教程:Tensorrt安装及使用
- 环境安装包:SD_webUI_Trt安装环境包.7z
(PS:文档作者的TRT一键体验包正在绝赞内测中,如果你需要Python的地方就一个AI绘画且没有使用秋叶包,那么可以试一试)
如果有能力安装TensorRT那都推荐去尝试一下(后续我在笔记本上 幻16星空版 4090 也装了一个发现提升并不是很大,但是也有1.5倍以上的加速,当然这可能是我自己这的原因)。如果没能力自行安装并且跑起来,那就别尝试了,你问别人不会得到除卸载以外的任何答案。
b. 其他加速算法
● LCM
- LCM论文:[2310.04378]
- LCM Lora论文:[2311.05556]
- LCM官网:Latent Consistency Models:
- LCM git仓库:luosiallen/latent-consistency-model
● SDXL Turbo
- HF链接stabilityai/sdxl-turbo
● SDXL Lighting
● Trajectory Consistency Distillation
根据论文说法,TCD 在质量和速度方面都提供了卓越的结果,超越了 LCM。相比 LCM,TCD 在高 NFE 下保持卓越的生成质量,甚至超过了使用原始 SDXL 的 DPM-Solver++(2S) 的性能(秋叶测试:没比 LCM 强什么)。
- 论文:[2402.19159]
TCD LoRa:该 LoRA 需配合 TCD 采样器使用,目前还没有在几个 UI 内实现。
- TCD SD1.5 LoRa:h1t/TCD-SD15-LoRA
- TCD SDXL LoRa:h1t/TCD-SDXL-LoRA
● OneFlow
- 说明文档:刷新AI作图速度,最快开源Stable Diffusion出炉
- 源码解析:OneFlow源码解析:Global Tensor
- diffusers:GitHub - Oneflow-Inc/diffusers
● Hyper-SD
字节跳动宣布推出Hyper-SD 一步蒸馏SD,支持SD1.5和SDXL。(高级版本的TCD蒸馏,也支持SD1.5版本,有LoRA可以直接用,最少一步。)
- 网页:Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis
- HF:ByteDance/Hyper-SD
- T2I Demo:Hyper SDXL 1Step T2I
- Scribble Demo:Hyper SD15 Scribble
- Webui可用:青龙圣者的动态
c. IC-Light
IC-Light的全称是“Imposing Consistent Light”,它可以给输入的图像重打光。目前IC-Light支持两种方式:基于文本引导和基于背景图来引导。
- git:lllyasviel/IC-Light: More relighting!
- 说明文档:ControlNet作者新作IC-Light:给图片重打光!
- Comfy:ComfyUI-IC-Light/README.md at main · kijai/ComfyUI-IC-Light
d. ELLA
是由腾讯的研究人员推出的一种新型方法,旨在提升文本到图像生成模型在处理复杂文本提示时的语义对齐能力。现有的扩散模型通常依赖于CLIP作为文本编码器,在处理包含多个对象、详细属性和复杂关系等信息的长文本提示时存在局限性。因此,研究团队提出了ELLA,使用一个时序感知语义连接器(TSC)来动态提取预训练LLM中的时序依赖条件,从而提高了模型解释复杂提示的能力。
- 主页:ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
- 代码:GitHub - TencentQQGYLab/ELLA: ELLA
- 论文:[2403.05135] ELLA
- Comfy节点:GitHub - ExponentialML/ComfyUI_ELLA
- 模型:QQGYLab/ELLA at main
- T5模型:google/flan-t5-xl at main
e. Hidiffusion
Hidiffusion是字节跳动和旷视推出的一个调整框架,由分辨率感知 U-Net (RAU-Net) 和改进的移位窗口多头自注意力 (MSW-MSA) 组成,Hidiff使预训练的t2i扩散模型能够有效地生成超过训练图像分辨率的高分辨率图像.
- 网站:HiDiffusion
- 代码:megvii-research/HiDiffusion
- Colab demo:hidiffusion_demo.ipynb
- comfy节点:florestefano1975/ComfyUI-HiDiffusion
6. 模型合集| 都整理好了,在这里
提示:不建议使用一部分国内的AI模型站(LibLibAI、海艺AI),其中曾出现过例如“霸王条款事件”(了解过自然知道,不了解的我也懒得说)等众多离谱操作,如有能力还是尽可能使用Civitai和hf。
a. 不推荐的模型

正常模型整个几块钱十几二十几的块钱的下载赚点辛苦费也就算了,平台上挂个会员下载也没啥可说的。种大几百的模型纯属智商税,这插件丢人都丢到国外去了。
挂羊头卖狗肉的纯噱头模型↑。
总之,除此之外类似性质的模型还有很多,注意分辨,不建议使用。
b. 综合模型社区
● Modelscope
● 抱脸(hugging face)
应该是最大的AI交流站,内有部分sd模型
- Hugging Face – The AI community building the future.
c. Stable diffusion AI绘画模型站
● Civitai
也就是常说的C站,使用最为方便,绝大部分模型都是从这里发布的。至少这里不是每个模型不管质量就只能说好,垃圾模型或离谱言论也会被人指出。(上不去别多问,不知道为什么就去tusi的C站镜像)
- civitai
● AITool模型交流站
上不去Civitai和Huggingface的可以使用这个网站,比较方便。
- AiTool.ai - Explore the world of AI
● 吐司AI
国内新晋AI模型站,因其方便免费的生成图功能等而广受好评(我推荐是因为这网站没搞过离谱操作)。特色是具有功能比较全的在线文生图功能。
d. 其他模型站/合集
● TI模型站
远古时期的ti模型站,主要分享ti模型为主,现状用处已经不是很大了
- Stable Diffusion Textual Inversion Embeddings
● 臭站
国内社群制作的Stable diffusion资源站,内容比较多但是目前似乎缺乏更新
● Stable Diffusion Models
● 建筑模型共享文档
7. 模型相关 | 我们保留了一点点垃圾数据
LyCORIS是项目名称,这里面包括 LoCon、LoHa、LoKr 等(这些是算法名称),这些不同算法出来的模型可以叫LoCon模型、LoHa模型、LoKr模型……,请不要将其混为一谈。
a. 推荐的好模型/不推荐的热门模型
推荐模型和不推荐模型懒得说了,垃圾模型更新太快不可能全都列举,大部分垃圾模型灾难性遗忘相当严重,比如墨幽人造人几乎只会出同一张脸。很多都是老生常谈的问题,但很多人还是把一堆答辩奉为圭臬。建议放下助人情节,嘲笑他人命运。
b. 模型基础
● 模型基础理论V2.0
从原理和模型结构上详解了模型的一些基本的东西,有助于帮助大家分别好模型和不好的模型。以及帮助大家自己制造比较好的模型。模型为啥推荐为啥不推荐,在这个文章都有答案。
- Model basis theory | Civitai
● clip与提示词的测试&clip修复
微笑测试:
- [調査] Smile Test: Elysium_Anime_V3 問題を調べる #1
- [調査] Smile Test: Elysium_Anime_V3 問題を調べる #2
- [調査] Smile Test: Elysium_Anime_V3 問題を調べる #3
clip修复:
- Skip/Reset CLIP position_ids FIX
c. 并不科学的Model Block Merge
注意,MBW相关内容请不要无脑的认为那一层是画什么的,现有的这一部分理论都是有限实践测试的内容,仅在部分条件下通用。
- Merge Block Weightedを使ってモデル合成をする方法|フェイさん
- [実験レポ] Model Block Merge で、 U-Net の各レイヤーの影響を調べる
- What is Block merging? (rentry.org)
- Merge Block Weight 魔法密录1.0正式版
mbw相关git地址
- MBW Gui:bbc-mc/sdweb-merge-block-weighted-gui
- SuperMerger:hako-mikan/sd-webui-supermerger
lbw(LoRA Block Weight)
- 使用方法:炜哥的AI学习笔记——Lora-Block-Weight 插件
- git仓库(内含一些内容,希望看完redme.md)hako-mikan/sd-webui-lora-block-weight
d. 从扩散模型中删除概念
可以删除模型中的某些概念,且对于模型其他部分的影响较小。
- 项目网站:Erasing Concepts from Diffusion Models
- 相关论文:[2303.07345] Erasing Concepts from Diffusion Models
- git仓库:rohitgandikota/erasing: Erasing Concepts from Diffusion Models
UCE概念编辑:
- 项目网站:Unified Concept Editing in Diffusion Models
- 相关论文:[2308.14761] Unified Concept Editing in Diffusion Models
- git仓库:rohitgandikota/unified-concept-editing
g. 生态互通
SD1.5的controlnet和lora等都可以无缝迁移到XL模型上,目前使用的是@Kijaidesign做的插件,项目地址:
- https://github.com/kijai/ComfyUI-Diffusers-X-Adapter
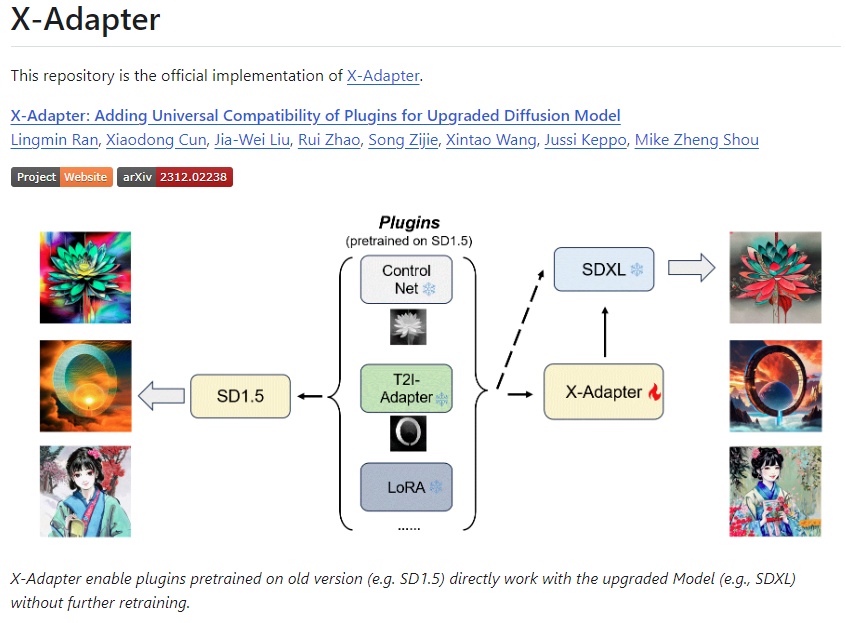
8. 训练相关 | 人人都可以炼丹,这太酷了
不建议使用使用任何所谓打着“降低炼丹门槛”名号,但是参数为固定预设值的一键炼丹炉,除非你想批量制造垃圾!
a. 相关链接
Finetune/LoRA/LyCORIS 差异详解重新理解模型训练
- 2024-02-24直播錄播[Finetune/LoRA/LyCORIS]
本文档作者制作的部分内容整理:
- Dreambooth网站:DreamBooth
- Dreambooth论文:[2208.12242] DreamBooth
- Dreambooth插件:d8ahazard/sd_dreambooth_extension
- Lora论文:[2106.09685] LoRA: Low-Rank Adaptation of Large Language Models
- Lora论文解读①:爆火的stable-diffusion微调方法lora论文逐段精读
- Lora论文解读②:LoRA(下):爆火的stable-diffusion模型微调方法
- 附加:【论文串读】Stable Diffusion模型微调方法串读
- TI论文:[2208.01618] An Image is Worth One Word
- TI git仓库:rinongal/textual_inversion
- DreamArtist论文:[2211.11337] DreamArtist
- DreamArtist git仓库IrisRainbowNeko/DreamArtist-stable-diffusion
b. 模型训练前置相关
前置知识By:秋葉aaaki
- 【AI绘画】过拟合、欠拟合是什么意思?AI训练前置知识(二)
- 【AI绘画】LoRA训练与正则化的真相:Dreambooth底层原理
二次元LoRA模型模型不建议无脑使用AnythingV3/5或AnyLora等模型(在因为某些原因Nai1无法作为训练底模使用的时候,Anything V5可以是很好的替代选择),真实LoRA模型不建议使用 墨幽 或MajicMix等模型。一般而言是想要在哪个模型上使用这个LoRA就用哪个模型训练。如果追求多模型通用,可以使用SD1.5本体(二次元可以使用NaiV1)
c. 推荐UP主&训练教程
● 青龙圣者
LoRA的详细训练教程推荐查看青龙圣者的视频教程,讲解极为详细
● 大江户战士
● 一般训练教程
- THE OTHER LoRA TRAINING RENTRY
- Hypernetwork training for dummies
● kohya_ss/sd-scripts
市面上见到的绝大部分教程视频、说明文档等内容,都是围绕这个展开的,git仓库地址:
sd-scripts的docs中文文档内容
- kohya_ss/docs/train_README-zh.md
- kohya_ss/docs/train_db_README-zh.md
- kohya_ss/docs/train_network_README-zh.md
另附:秋叶魔改的LoRA训练器,中文UI界面更直观,并且自带tagger等功能,十分方便。
社群、交流站的训练教程
- Stable Diffusion 训练指南 (LyCORIS)
……(自己b站找吧,太多了)
● HCP-Diffusion
HCP这东西你用我推荐,反正我不用。HCP-Diffusion/HCP-Diffusion-Webui的github仓库地址(不推荐使用HCP-Diffusion-WebUI,因为全是bug)
- 7eu7d7/HCP-Diffusion: A universal Stable-Diffusion toolbox
- 7eu7d7/HCP-Diffusion-webui: webui for HCP-Diffusion
相关教程链接:
- Welcome to HCP-Diffusion documentation! — HCP-Diffusion 0.1.0 文档
d. 数据集
● 常用数据集
部分常用、经常提到的数据集(更多其他的数据集可以自行去搜索,篇幅原因只放几个常见的):
- 原神合集:animelover/genshin-impact-images
- Danbooru 2023:nyanko7/danbooru2023
- Danbooru 2021:Danbooru2021: A Large-Scale Crowdsourced and Tagged Anime Illustration
- NijiJourney数据集:Korakoe/NijiJourney-Prompt-Pairs
- NijiJourney-pixivLinaqruf/pixiv-niji-journey
- NaiV3整流:shareAI/novelai3
HakuBooru:动画风格图像的文本图像数据集生成器,该项目是为了防止过度使用爬虫脚本干爆网站。
- KohakuBlueleaf/HakuBooru: text-image dataset maker for anime-style images
deepghs:已知游戏角色的数据库。数据库每天刷新一次,托管在huggingface - deepghs/game_characters上。
- GitHub - narugo1992/gchar: Crawler and cleaner of data for novelai embedding's training
● 数据集处理
- 手动打标GUI:arenasys/sd-tagging-helper
数据集预处理包,批量处理图片、标签、过滤等
- waterminer/SD-DatasetProcessor: 🛠一站式的图片数据集预处理工具包
一个针对单张图片的DanBooru标签精修小程序
- Aleiluo/danbooruTagEditor: 针对sd训练的danbooru标签编辑器
lax团队针对XL训练研发的开源美学评分与数据清洗工具组,可用于大数据集训练的预处理,美学评分与质量词自动标注
- Anime Thetic - a Hugging Face Space by Laxhar
● imgutils
一个方便和用户友好的动画风格的图像数据处理库,集成了各种先进的动画风格的图像处理模型。
- 代码:GitHub - deepghs/imgutils
- 文档:Welcome to imgutils’s Documentation — imgutils 0.4.1 documentation
f. D3PO
- 论文:[2311.13231] Using Human Feedback to Fine-tune Diffusion Models without Any Reward Model
一个评分模型:
这个模型作者正在用来搞一些自动的东西,有时间搞好了大概会发出来:
- chikoto/ConvNeXtV2-IllustrationScorer
自动炼丹
- 全自动番剧数据集:cyber-meow/anime_screenshot_pipeline
利用waifuc可以自动获取训练所需数据集:
- 工具链接:deepghs/waifuc: Efficient Train Data Collector for Anime Waifu
- 说明文档:https://deepghs.github.io/waifuc/main/index.html
- C站文档:V1.5 Auto-Waifu-Training IS COMING! | Civitai
基于Waifuc自动炼化炼丹的角色模型库:「narugo1992」的C站主页。如果纯新人且没有学习的需求(仅为了跑图)的话,那么有什么想要的角色LoRA模型可以到这里找找,很多时候自己练出来的效果是比不过这种自动化炼丹的。
- narugo1992 Creator Profile | Civitai
CyberHarem一键炼丹,自动化训练工具
- deepghs/cyberharem:Cyber Harem of All the Waifus in Games,Mua~
使用此自动炼丹工具,训练出的模型比绝大部分的手工炼制的模型都要好
=DeepGHS=