



1.视频讲解
具体视频跳转至b站查看https://www.bilibili.com/video/BV1gt4y1d7e4/?spm_id_from=333.1350.jump_edge
2.训练入口
在吐司主页点击“在线训练”即可进入
3.添加与处理数据集
3.1添加数据集
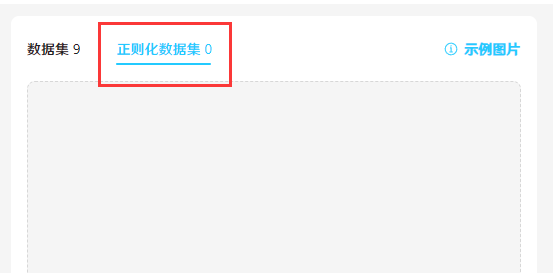
数据集
目前支持的格式有png/jpg/jpeg,最多可添加1000张图片进行训练
已上传的图片可以点击右上角进行删除
这里建议大家尽量上传更高清的图片以得到更好的训练结果
可以使用增强后的数据集,例如:裁剪分割、图像镜像/翻转

正则化数据集
正则化技术广泛应用在机器学习和深度学习算法中,其本质作用是正则化起到降低训练素材某个权重的作用,防止过拟合、提高模型泛化能力 。
我们可以通过这里来上传正则化数据集,正则化数据集可以使用用于训练的底模生成。
对于完全不熟悉训练流程的纯小白来说,不使用正则数据集可能会得到更好的效果。
请勿上传血腥/暴力/黄色/涉政等任何违规图片,多次上传违规图片可能会封禁账号
3.2批量裁剪

裁剪方式:
聚焦裁剪:根据画面的主体内容进行裁剪
中央裁剪:裁剪画面的中央部分
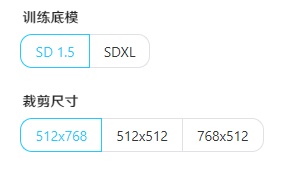
根据训练底膜选择裁剪尺寸
SD1.5可选尺寸:
512x468
512x512
768x512
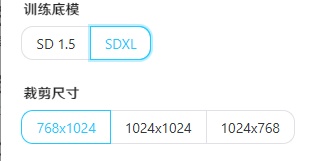
SDXL可选尺寸:
768x1024
1024x1024
1024x768
3.3自动打标

每个上传的图片都会被自动打上标签,标签内容点击图片即可查看。除此之外还可对图片标签进行添加与删除。
如果训练角色想要固定某些特征,那么可以删除该特征的提示词
任何AI自动打标都不可能100%准确,有条件尽可能人工筛查一遍,剔除错误标注,从而提升模型的质量
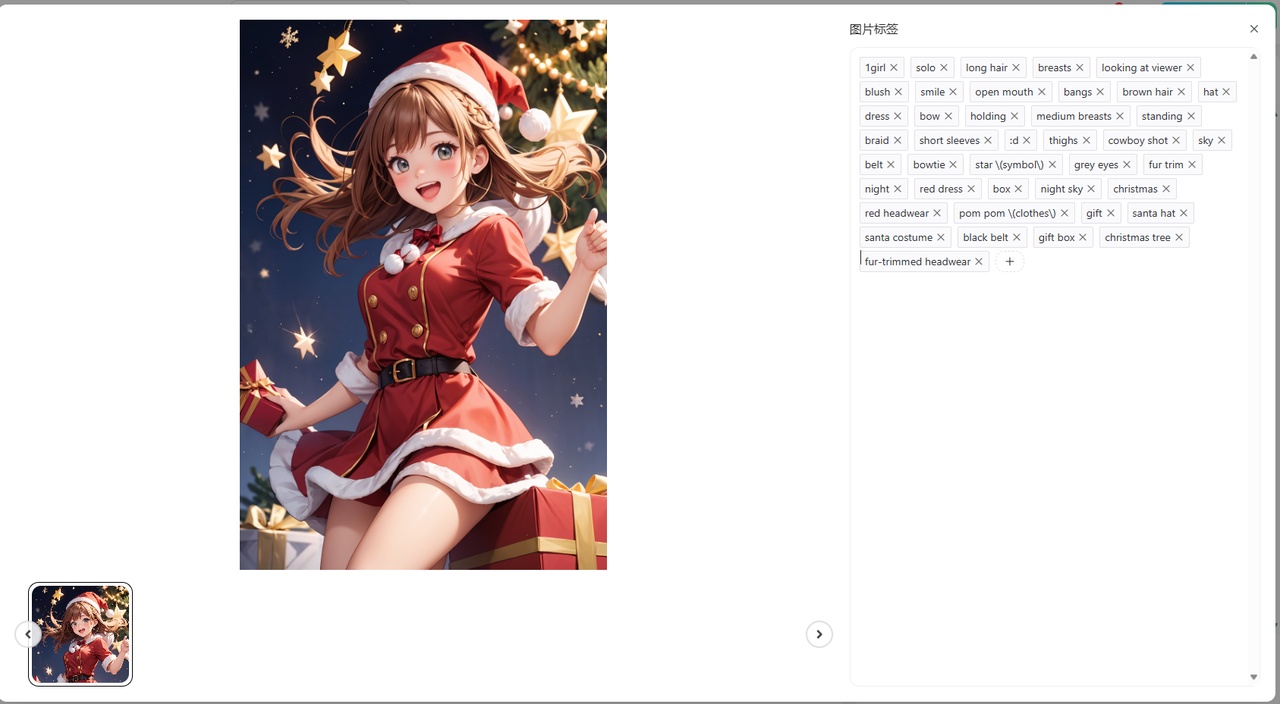
3.4批量加标签

目前支持对图片进行批量添加标签,可以自行选择添加到行首或者行尾,一般来说是添加到首行作为触发词使用。

4.训练参数设置
4.1设置重复次数

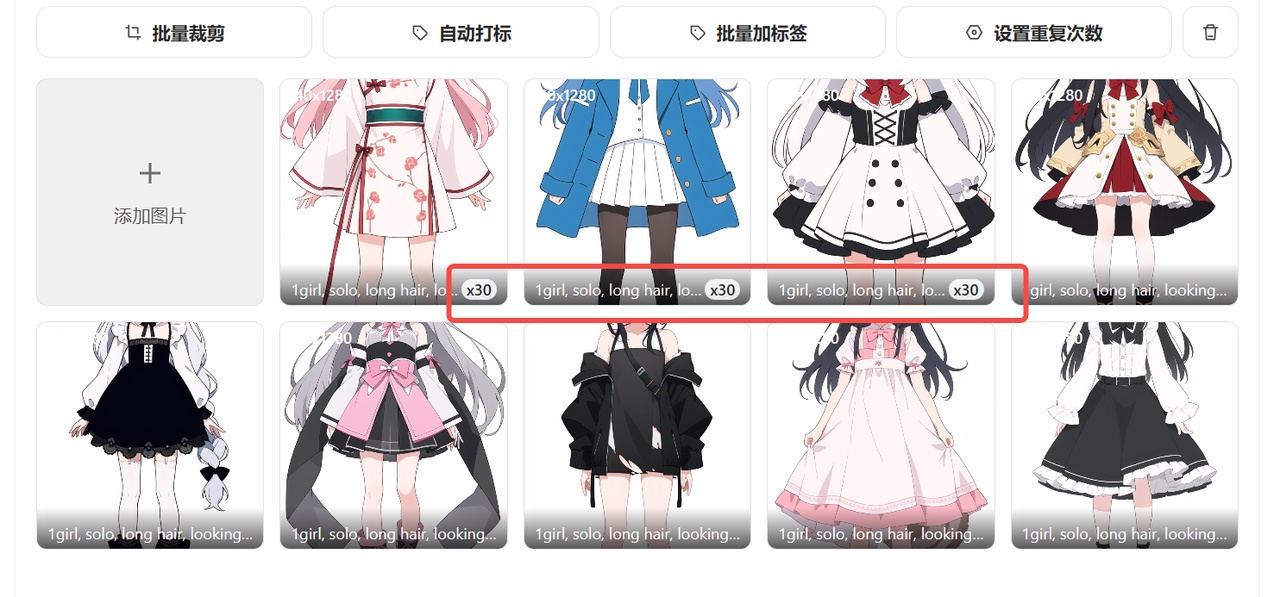
图片训练的重复次数,即repeat参数。一般而言在本地训练时需要单独到训练集的文件夹内调整该项参数

而在吐司的在线训练工作台里,我们可以从这个地方更改单独图片的重复次数,如果在上面上传了增强的数据集,那么就可以在这里单独设置不同的重复次数
4.2基础模式
模型主题&底模选择:模型根据不同的主题预设了不同的训练参数,选择合适的底模会让你的模型训练事半功倍哦!需要注意:不同的XL模型之间的LoRA大概率不能通用,请谨慎选择底模
二次元人物:可选底模AnythingV5/Animagine XL/Kohaku-XL Delta,训练SD1.5的二次元人物LoRA需要使用AnythingV5,训练SDXL的LoRA需要使用Animagine XL/Kohaku-XL
真实人物:可选底模EpiCRealism (SD 1.5)/Juggernaut XL(SDXL)。已经预设好训练的部分参数,根据自己需要选择底模调整相关参数即可
2.5D:可选底模DreamShaper/国风3 GuoFeng3/DreamShaper XL1.0/国风4 GuoFeng4 XL,训练SD1.5的LoRA需要使用DreamShaper/国风3 GuoFeng3,训练SDXL的LoRA需要使用DreamShaper XL1.0/国风4 GuoFeng4 XL
标准:预设使用SDXL1.0/SD1.5 base作为训练底模,如非特殊需要,不建议使用
单张重复次数 (Repeat):Repeat指的是AI对每一张图片学习的次数,这里的Repeat仅对没有单独设置Repeat的图片生效
训练轮数 (Epoch):Epoch指的是AI对你的图片学习的一个循环。所有的图片都完成了Repeat后,这样就是一个Epoch。
总步数(Steps):详见表格下方的补充
模型效果预览提示词:这里的提示词是用于每个Epoch保存的版本的预设出图,用于预览模型的训练效果
此参数不影响训练的效果和模型的质量,仅作为实时预览图参数
总步数的计算公式是:
(训练集里面的图片数*Repeat*Epoch)
总步数直接影响模型训练的算力消耗,步数越多算力消耗越大
4.3专业模式
新手不建议使用专业模式
单张重复次数(Repeat):Repeat指的是AI对每一张图片学习的次数
训练轮数(Epoch):Epoch指的是AI对你的图片学习的一个循环。所有的图片都完成了Repeat后,这样就是一个Epoch。
总步数的计算公式是: (训练集里面的图片数量*Repeat*Epoch)
总步数将直接影响模型训练的算力消耗,步数越多,算力消耗越大
种子(seed):(玄学,随机即可)
文本编码器学习率:调整整个模型对于tag的敏感度
如果你在生成图片过程中发现了多余的物品,那么就需要降低TE学习率;如果您很难在不对提示进行大量权重的情况下使内容出现,那么你就需要提高TE学习率。
Unet学习率:模型的学习速度和程度
高的学习率可以使AI学习的更快,但是可能导致过拟合。如果模型不能复刻细节,生成图一点都不像,那么就是学习率太低了,尝试增加学习率
学习率调度器:调度器指的是"如何设置学习率的变化方式"
优化器:优化器设置用于在训练过程中更新神经网络权重的方式。为了智能地进行训练,提出了各种不同的方法。
训练网格大小 Dim:DIM表示神经网络的维度,维度越大,模型的表达能力就越强,模型最终的体积也会越大。
DIM不是越大越好,对于单一角色LoRA而已,DIM完全没有必要开128
训练网络Alpha值:
在实际(保存的)的lora权重值保持较大的同时,在训练时始终以一定比例削弱权重,以使权重值看起来较小。这个“削弱比例”就是Network Alpha。
Network Alpha值越小,保存的LoRA神经网络的权重值越大。
打乱标签:
通常情况下,标题中的单词越靠前,其重要性越高。因此,如果单词的顺序固定,后面的单词可能无法得到很好的学习,或者前面的单词可能与图像生成产生意外的关联。通过每次加载图像时随机调换单词的顺序,可以修正这种偏见。
保持第N个token:指定的前n个单词将始终保持在标题的最前面,可以通过这个去设置触发词。
在这里,“单词”指的是以逗号分隔的文本。无论分隔的文本包含多少个单词,它都被视为“1个单词”。例如,对于“black cat, eating, sitting”,“black cat”被视为1个单词。
噪声偏移:在训练中添加噪声偏移来改良生成非常暗或者非常亮的图像,不宜开太大,尽量在0.2以下
多分辨率噪声衰减率:
多分辨率噪声迭代次数:
卷积层维度:
卷积层Alpha值:
提示词,采样算法:这里的提示词与采样算法是用于每个Epoch保存的版本的预设出图,用于预览模型的训练效果
5.训练过程
因为一台机器只能同时运行一个模型训练任务,所以面对可能出现的排队情况还请各位烘焙师们耐心等待,我们将会尽快为您准备好训练机器。也可以在夜间进行错峰训练哦
6.模型测试
目前可以找到例图合适的模型发布后,不上传展示图片(没有用于展示的图片,不会分发到首页),等待部署完成后即可在工作台测试自己的模型。
7.模型发布/下载/重新训练
在训练完成后您将看到每个Epoch的四张预览图,您可以从中挑选满意的作品发布在吐司或保存在本地。如对本次训练不满意可在右上角查看训练参数、重新训练,具体的调整参数的方法可以查看上面的说明。