



前言
元素同典:确实不完全科学的魔导书【原文】如下,本文章内容大量借鉴/引用元素同典原本的内容,故本问内容所有资料同样均可被自由引用。最终解释权归 元素法典策划组&千秋九 所有
这是一篇提示词指南,旨在为刚刚接触 AI绘画 的萌新快速上手 AI 作画。
笔者(在本处与下文代指本文的所有笔者)将简单分析 parameters 中乱七八糟的基础逻辑和应用,如有错误或疏漏之处,也请多多包涵,或者直接对元素法典策划组进行发癫也行。欢迎各位在批注中留下对于本文的建议/意见。
本文基于无数高阶魔法师的经验与对 parameters 相关的内容进行挖掘所得成果总结而成,且包含许多个人理解和主观观点。非常欢迎各位前往元素法典交流群讨论。
由于本魔导书内容较多且篇幅较长,请妥善利用目录功能及文档内搜索功能寻找需要的资料。
准备工作:神奇AI绘画 在哪里?
本段内容直接复制Stable Diffusion潜工具书的内容,不想看可以不看,“透明版本”链接:
● SD WebUI
有能力的可以自行部署stable dffusion相关UI,不过一般而言更推荐下面的整合包(工具)
- git仓库AUTOMATIC1111/stable-diffusion-webui
SD WebUI秋叶整合包与SD Webui绘世启动器
- 【AI绘画·11月最新】Stable Diffusion整合包v4.4发布!
SD WebUI秋叶整合包A卡适配版
- 【AI绘画】Stable Diffusion A卡专用整合包(DirectML)
SD WebUI贴吧一键整合包
搭载了dreambooth等插件,方便的自己炼制大模型(最低要求12G显存)。能够有效避免自行安装dreambooth插件时出现的各种问题。同时贴吧整合包适配A和和I卡,更方便使用
- WebUI | SD - WebUI 资源站 (123114514.xyz)
WebUI设置、预设文件搬迁(更换整合包)
- 【AI绘画】换整合包/自部署WebUI如何搬家设置与模型?
● ComfyUI
SD Comfy秋叶整合包:
- 【AI绘画】ComfyUI整合包发布!解压即用 一键启动 工作流版界面 超多节点 ☆更新 ☆汉化 秋叶整合包
SD ComfyUI 无限圣杯AI节点:
无限圣杯工具是由只剩一瓶辣椒酱-幻之境开发小组开发的一款基于SD ComfyUI 核心的 Blender AI 工具,它将以开源&免费的方式提供给 blender 用户使用。
- 无限圣杯AI节点(ComfyUI) 使用者手册 (shimo.im)
Comfy的其他整合包/工作流:
- 懒人一键制作Ai视频 Comfyui整合包 AnimateDiff工作流_哔哩哔哩_bilibili
Comfy使用其他模型
- city96/ComfyUI_ExtraModels: Support for miscellaneous image models.
书写你的第一段咒语
当代赛博法师使用电子魔杖、虚拟魔导书来无中生有创造出美丽的图案,尽管更多人可能认为我们在成为弗兰肯斯坦。
咒语是什么?
在 AI绘画 中,我们使用一段 prompt 来引导 AI 使用“噪点图”反向扩散从而召唤出我们最后的图像。
Prompt (提示词,又译为关键词)通常由英文构成,主要内容为以逗号隔开的单词/词组/短句(二次元模型),有一些模型可以使用自然语言进行描述。除了英文之外prompt 还可以识别一些特殊符号。
AI 会通过寻找符合关键词描述的方向而有明确指向地去噪点(diffuse)。同样,如果包含 Negative Prompt(负面关键词),AI 就会尽可能避免含有负面相关要素的部分。换句话说,prompt 就像是哈利波特里面的咒语,它直接决定了最终我们会得到什么。
AI 对于关键词的辨识以从前到后为顺序,以逗号为分割。对于基本操作,可以以大括号、小括号、中括号调整权重。在 WEB-UI 中,小括号增加为 1.1 倍权重,中括号减弱为 0.91 倍权重(相当于除 1.1),多次嵌套括号效果相乘。但大括号在 WEB-UI 中默认并没有用,在 NovelAI 上则会增加为 1.05 倍权重。
Cheat sheet:
a (word) - increase attention to word by a factor of 1.1
a ((word)) - increase attention to word by a factor of 1.21 (= 1.1 * 1.1)
a [word] - decrease attention to word by a factor of 1.1
a (word:1.5) - increase attention to word by a factor of 1.5
a (word:0.25) - decrease attention to word by a factor of 4 (= 1 / 0.25)
a \(word\) - use literal () characters in prompt
With (), a weight can be specified like this: (text:1.4). If the weight is not specified, it is assumed to be 1.1. Specifying weight only works with () not with [].
If you want to use any of the literal ()[] characters in the prompt, use the backslash to escape them: anime_\(character\).
On 2022-09-29, a new implementation was added that supports escape characters and numerical weights. A downside of the new implementation is that the old one was not perfect and sometimes ate characters: "a (((farm))), daytime", for example, would become "a farm daytime" without the comma. This behavior is not shared by the new implementation which preserves all text correctly, and this means that your saved seeds may produce different pictures. For now, there is an option in settings to use the old implementation.
NAI uses my implementation from before 2022-09-29, except they have 1.05 as the multiplier and use {} instead of (). So the conversion applies:
their {word} = our (word:1.05)
their {{word}} = our (word:1.1025)
their [word] = our (word:0.952) (0.952 = 1/1.05)
their [[word]] = our (word:0.907) (0.907 = 1/1.05/1.05)
See https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features for full details and additional features.因此,一针见血的关键词才是我们所需要的,不建议咏唱不必要的咒语音节。
擦亮你的法杖
工欲善其事,必先利其器。
伏地魔都会追随老魔杖,那赛博法师又怎能不入乡随俗?
在 AI绘画 中,如果说 prompt 是咒语,那旁边的参数面板就是法杖。
这一些参数就是你的杖芯、杖柄,或许还有其他世界穿越来的附魔也说不定?
选择你的采样方法与调度类型:Sampler & Scheduler
开始调整所有参数之前,请选择你的采样方法。“请选择你的捍卫者”。 WEB-UI 都内置了许多采样方法,包括且不限于最常用的 Euler A 和 Euler, 以及原生默认的 LDM 等 。
采样方法组成了图片生成的第一大要素,它决定同样的 prompt 下 AI 会选择以何种方式去噪点化以得到最终图片。同时,它还会决定运算速度。
其中,你是否注意到某些采样器名字里带了一个字母 a: Euler a / DPM2 a / DPM++ 2S a。这些就是Ancestral 采样器,这些采样器会在每个采样步对图像添加噪声,就是其采样结果图片不会收敛。
调度类型简单而言就是去噪速度。常见的调度类型有:Karras / Sgm_uniform / Exponential / ddim_uniform……,目前推荐使用 Exponential 方法,可以得到更好效果。
迭代数量/采样次数:Sampling Steps
首先,在介绍关于迭代的理论之前,需要说明的是迭代并不总是越多越好。
对于不同的模型也有不同的理论:
例如 DPM A 和 Euler A 都是所谓的 非线性 迭代方法,它们的结果并不会因为迭代增加而无休止地变得更加优秀,在大于一定的迭代值之后反而质量会快速下滑。
而 DDIM / Euler 等 线性 迭代方法则恰恰相反,质量往往依托于迭代的次数。但也存在边际效应的问题,当迭代大于一定程度时,再增加迭代次数也不会让画面产生显著变化。
因此,实际使用时往往需要根据画布大小和目标是否复杂来综合考虑。对于正常画布,使用 Euler A /UniPC 等低数要求算法的迭代次数通常推荐 12 或以上(笔者本人一般使用Euler A 20Steps),而使用 DPM2 A 等高步数要求算法则往往要求更高一些。使用LCM等优化方式,迭代次数可以非常低,部分模型甚至可以“一步出图”
我的魔导书在哪里?
咒语的基础理论已经了解了,但此时此刻我们对于魔法的释放还是一头雾水:哪里去获得 prompt?又有哪些 prompt 是我们真的需要的?
在最理想的情况下,一位赛博魔法师首先应当试着去理解 danbooru.donmai.us,这是 NAI 和一些二次元模型的重要训练来源,也是绝大多数关键词的出处(至少覆盖 80%+),所以在里面找到的引用数大于 2000 的 tag 在绝大部分二次元模型里基本都可以直接当作 prompt 使用往往都能出效果,你甚至还能发现诸如颜文字当做 prompt 的惊人用法——而这都是可行的。但 danbooru 的访问需要跨越屏障,较为不便。
而除此之外还应该自己去收集可以用做 prompt 的材料,但是一个人上路太孤独了,拿着这把全村最好的法杖吧!
去寻找各种各样的帖子或者指南。抽丝剥茧地借鉴前人经验,批判思考地获取其中的精华(前人可能会因错误习惯而被干扰),也能得到不少效果很棒的 prompt。
闭目凝神,咏唱咒语
总而言之,你查阅资料或突发奇想,得到了一些咒语。将它填入第一栏,然后再在第二栏填入随处可见的通用反咒(Negative Prompt),点击 Generate,你的第一段咒语就完成了(笔者在此演示最简单的召唤术):
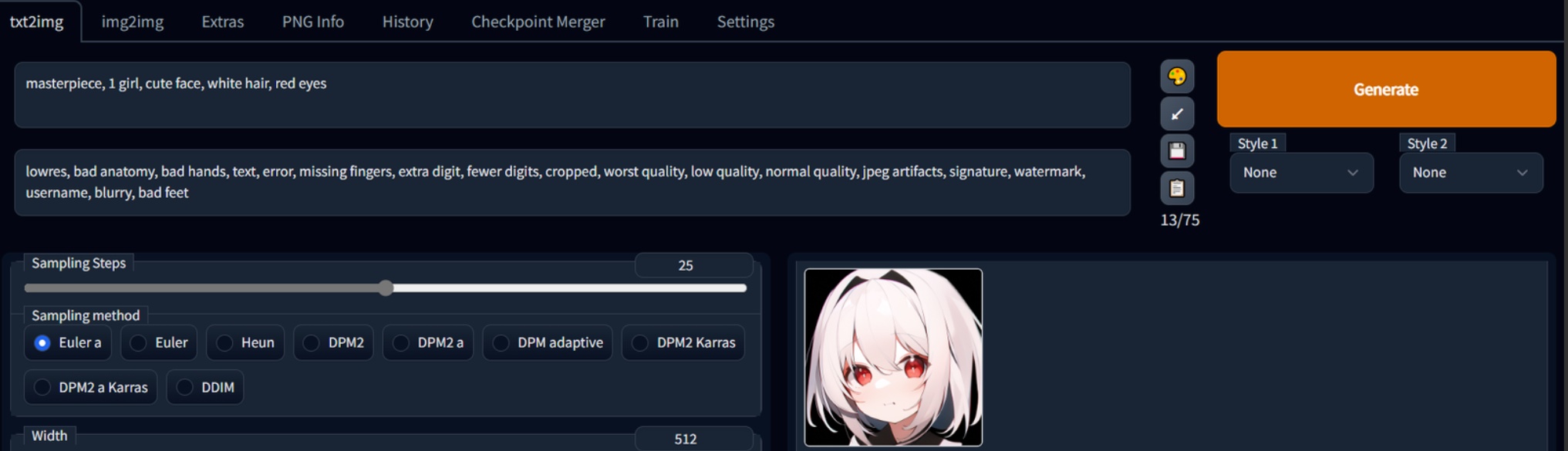
masterpiece, 1 girl, cute face, white hair, red eyes以防有人没查到——反咒是:
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, bad feet如果充分理解了前文内容,并且咏唱地不那么夸张,那么第一次施法往往将无惊无险地获得成功。现在你已经脱离麻瓜范畴,拥有成为魔法学徒的潜质了,向着魔法的大门前进吧!
咒法二次不完备进阶
Once we accept our limits, we go beyond them.
我们至今为止的所有努力,并非全部木大。
权与重
上文提到了关于 ()、[] 的使用。以防刚把魔杖捂热的新魔法师看到这里已经忘了它们是什么意思 —— 一对小括号意味着把括起来的 prompt 权重 * 1.1,中括号则是 / 1.1,大括号在 WEB-UI 中无调整权重作用,且会被作为文本而解析。
如果因为某些需求而要大量抬升权重,可以对 prompt 进行多次括号,比如((((prompt)))),这意味着将它的权重 * 1.1 四次,也就是 1.4641。但这个写法太吓人了,数括号也很浪费时间,所以应该直接为一个 prompt 赋予权重:
(prompt:权重乘数)外层一定是小括号而非其它括号。比如 (red hair:1.5) 将直接给 red hair 赋予 * 1.5 权重,清晰简洁,便于自己回顾和他人理解,强烈推荐。
但务必请不要做出诸如 ((red hair:1.5)) 的奇怪写法。虽然在大多数情况下,它们的确会产生互相叠乘的正常效果,但在某些离谱的情况下则会导致权重无效。
而除了整词权重之外,也可以进行部分权重,比如如下例子:
1 girl, white long (messy:1.2) hair, red eyes将专门对 messy 部分赋予 * 1.2 权重,其它部分不受影响。
高权重的元素会在画面中有着更大的占比或更强烈的存在感或更多的数量,是能可观地影响构图的原因之一。笔者非常不建议给出十分离谱的权重值,这个也包括负面权重,三个小括号也只有 1.3 左右,而一般来说 1.6 就已经很极端了,再高至例如 2.0 只会在大多数情况下让咒语变成召 唤 古 神。
高级咒术解析
上述的小括号、中括号与带权重小括号都属于低阶语法,比如(((prompt)))。而接下来要介绍的是更长更复杂一些的高阶语法。
高阶语法都以 [] 作为外层包括,包括分步描绘、融合描绘两种,使用高阶语法时这一对中括号不会让权重降低。高阶语法内可以嵌套低阶语法,低阶语法内也可以嵌套高阶语法——但为了交流方便不建议嵌套,高阶语法之间能否互相嵌套因具体情况不同而异,下文会做出介绍。
下列介绍全部基于编纂本篇时推出的最新版 WEB-UI,对于 Comfy 或较远古版 WEB-UI 可能不适用。
首先介绍分步描绘的各种形式:
[from:to:step]
[from::step] (to 为空)
[:to:step] (from 为空)
[to:step] (奇怪但没问题的格式,非常不建议)它的作用是让 prompt 在达到 step 之前被视为 from,在达到后视为 to。若是在对应位置留空则视为无对应元素。step 为大于 1 的整数时表示步数,为小于 1 的正小数时表示总步数的百分比。
比如 a girl with [green hair:red hair flower:0.2] 会在前 20% 步数被视为 a girl with green hair,在后 80% 步数被视为 a girl with red hair flower。需要注意这两个描述之间的兼容性和覆盖——在步数合适的情况下,最后形成的人物会拥有绿色头发和红色花饰,但也可能因为颜色溢出导致头发也变为红色,毕竟后 80% 没有绿色头发的限定,AI 完全可以自己理解一个随机的发色。
在最新版中,分步描绘可以嵌套,形如 [from:[to:end:step2]:step1] 的语句是可以被正确识别的。且分步描绘现在支持逗号分割,形如 [1 girl, red hair: 2 girls, white hair:0.3] 的语句也可以被正确识别。
分步描绘不特别擅长细化细节,与其分步描绘不如将细化部分直接写入持续生效的部分。分步描绘更擅长在画面初期建立引导,大幅影响后续构图或画面生成。
需要注意的是,分步描绘具有视觉延后性——当要求 AI 在比如第 20 步开始描绘另一个不同的物体时,可能在比如第 24 步(或更晚)才能从人眼视觉上感知到另一个物体勉强出现在画面中。是因为steps的原因,很多时候前面的step,人眼可能是看不出来新的事物的(这跟你不开启LCM等加速的情况下step开到5以内是一个道理)。
然后介绍融合描绘的两种形式:
[A | B]它还有可无限延长版:
[A | B | C | ...]对于形如 [A | B] 的第一种,AI 将在第一步画 A、第二步画 B、第三步画 A...交替进行。而对于无限延长版,则变为第一步画 A、第二步画 B、第三步画 C...循环往复交替进行。
融合描绘不可嵌套,但同样支持逗号分割。融合描绘擅长将两种事物混合为一起,比如 a [dog | frog] in black background。
这两个高阶语法有着明显的区别,尤其是在高步数下更不可以一概而论。分步描绘的 40 步 A 再加上 40 步 B 最后可能形成一个带有 B 基底特征的 A,但它会表现出明显的分立感。而融合描绘的 40 步 A 再加上 40 步 B 最后将形成简直像是化在一起的融合体。
短元素,中元素与长元素
咏唱大致有着三种不同形式——最常见的直接咏唱、稍不常见的短句咏唱和堪称行为艺术一般的长咏唱。
假设要生成一个有着黄色头发、蓝色眼眸、白色上衣、红色裙子、黑色裤袜的全身坐姿二次元美少女,且强调服饰颜色,那么这三种咏唱分别看上去大概是这样的:
直接咏唱(pitch 式咏唱):
masterpiece, best quality, 1 girl, (blue eyes), (yellow hair), (white clothes), (red skirt), (black leggings), sitting, full body短句咏唱(AND 强调咏唱):
masterpiece, best quality, 1 girl, (blue eyes) AND (yellow hair), (white clothes) AND (red skirt) AND (black leggings), sitting, full body长咏唱(自然语言咏唱):
masterpiece, best quality, (1 girl with blue eyes and yellow hair wearing white clothes and red skirt with black leggings), sitting, full body注意短句咏唱的 AND 必须是三个大写字母,AND 两侧的小括号是不必要的(但建议加上),这是一个专用语法。此外,该语法并不能应用于所有采样方法,例如 DDIM 就不支持 AND,会导致报错。
我的法杖不听话了?
有的时候会返回黑色图片或者直接没了,黑色图片俗称黑图。
图直接没了的最简单直接的原因是显存爆了,查看后台是否出现类似于 CUDA out of memory,如果出现那就真的是显存爆了,提高配置或降低画布大小吧。
不过在更多时候,法杖不听话的表现并不是黑图。例如在比 2k*2k 稍小一些的 1.2k*1.2k 画布中,可能会出现如下情况:

masterpiece, 1 girl, white hair, red eyes明明要求 1 girl,但为什么它生成了 2 个人?
简单来说就是图太大了,超过了模型适合的使用范围。但对于这段如此简单的咒语而言,将画布缩减为 1.2k*1.2k 依然显得有些太过自由了。画完一个美少女之后该怎样填充剩下的画布呢?AI 可能会使用纯色背景、构筑一个简单的空间,但它更可能会做的事情是——把已有的东西重复再画一份。(如果往深处讲,那就要涉及到目前 SD 训练模型时的方法导致目前 AI 的局限性。SD 训出来的模型其实并不理解数字,对于 AI 而言 1 girl 和 2 girls 并不互相冲突,再加上懂得都懂的那些训练集里的各种共有 tag 会给它们一定程度上的联系,所以在无物可画但必须要填充画面时倾向于多画一份。)
所以要解决这个问题也不难。减小画布,限制它的自由度即可。

masterpiece, 1 girl, solo, white hair, red eyes, black gown, in room, chair, vase, red carpetHigh res. fix 也能解决此类问题,但它是利用先在小分辨率渲染再放大到目标分辨率的方法。最符合字面意义的做法还是直接从根源下手。
最后是一些碎碎念...
不必为每个 prompt 都加上过多小括号来提高权重,如果你发现你真的需要给绝大多数元素都加上四五个小括号才能让你想要的东西确保出现,那么更建议酌情普遍删掉一些括号,改为拉高 CFG Scale ,比如 12 甚至 14。在极端情况下,给单个 prompt 加上过多权重,可能会导致古神。
除非明确清楚重复 prompt 意味着什么、且有强烈的对应需求,否则不建议重复输入 prompt。重复输入 prompt 的语义相当复杂,不在入门范畴内。
不必保持如此神秘的敬畏...
既知が世界だ,未知はいらない!
未知的,不需要。已知的,才是世界!
魔法的极致或许是科学
了解各类 prompt 的存在并不意味着就掌握了一切,摘抄别人的 prompt 囫囵吞枣地使用也不是上乘。如果想要让 AI 创作出更佳的作品,那么还需要深入了解各个 prompt 到底有着何等作用,以备日后使用。各个 prompt 之间的互相影响如同魔法反应一样,大多数情况下并不像是仅仅简单字面意义上的互相叠加那样简单。
举个例子,比如 an extremely delicate and beautiful girl 其实就会导致不少风格化表达被覆盖;而 light 用作颜色在很多情况下不是指淡而是发光,甚至在某些稀有的组合里还专指黄光;让一个角色手上握着武器可能不仅仅要 holding weapon 还需要加上 weapon 本身,诸如此类。
因此,各类科学分析方法甚至是研究方法都是有必要的。
元素魔法?定性定量分析法!
授人与鱼不如授人与渔。
对于同一组 prompt 而言,魔法师们常以良品率作为无意识的定性分析的结果,但对于其它方面也可以进行分析,比如单个 prompt。
SD 模型基于种子(seed)来进行生成,如果条件都相同,则生成的图必然相同。利用这个特性可以对不同的 prompt 进行定定性分析,填写一个种子,固定其它参数,固定绝大多数 prompt,然后调整/添加想要测试的那一个 prompt,来确定它的作用、效果。
想知道一个 prompt 是否真的有意义吗?是否真的有传言所说的种种作用?它和某些组合的搭配真的很好吗?来定性分析它吧。
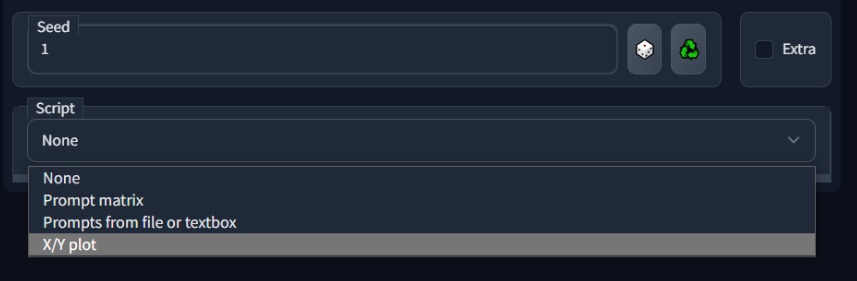
介绍如何使用 Script 中的 X/Y plot(X/Y 坐标图)来辅助分析。注意 seed。

在输入框输入等待被替换的 prompt,然后使用 X/Y 的 Prompt S/R 功能。
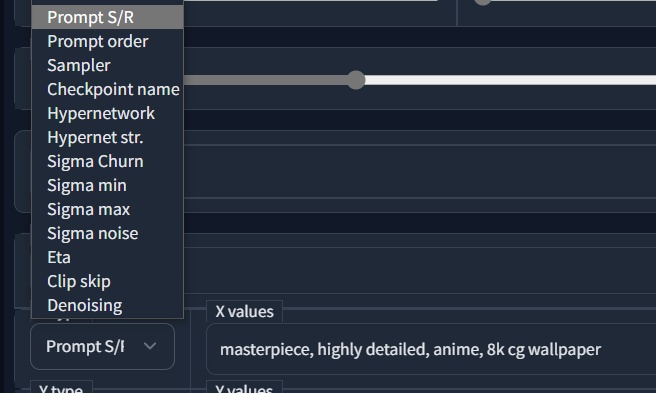
在右侧的 X values 中进行填写。第一个 prompt 是被替换位点,而后面的则是希望替换为的 prompt,最后生成即可得到结果。
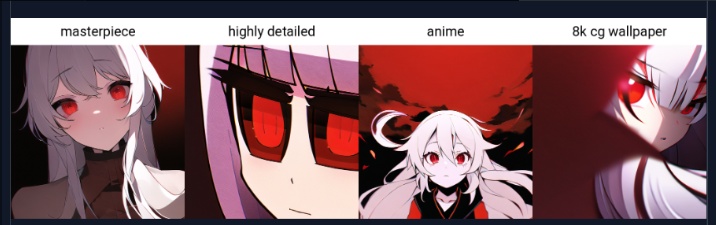
字数限制请看下篇:提示词入门教程·下篇:《元素同典:确实不完全科学的魔导书》